input_df <- expand.grid(
list("year" = c(2010, 2011),
"locality" = c("Bascharage", "Luxembourg"))
)
input_df$n_offers <- c(123, 101, 1230, 1010)
input_df$average_price_nominal_euros <- c(234, 345, 560, 670)
input_df$average_price_m2_nominal_euros <- c(23, 34, 56, 67)12 Testing your code
Testing code is crucial, and we all do it in some form or another. The problem is that it is not something that we do consistently: usually code gets tested at the beginning of a project, but then, as we start focusing on the analysis more and more and need to respect deadlines, testing gets forgotten.
In this chapter, you are going to learn how to make testing your code consistent and, very importantly, fully automatic. Just like in the previous chapter, the key is to write everything down. Don’t just do a little test in the console to see if the function you’ve just written works as expected. Write it down! And don’t rely on future you to run tests, because future you is just as unreliable as you are. Tests need to be run each time any of the code from a project gets changed. This might seem overkill (why test a function that you didn’t even touch for weeks?), but because there are dependencies between your functions, a change in one function can affect another function. Especially if the output of function A is the input of function B: you changed function A and now the output of function A changed in a way that it breaks function B, or also modifies its output in an unexpected way.
There are several types of tests that we can use:
- unit testing: these are written while developing, and executed while developing;
- assertive testing: these are executed at runtime. These make sure, for example, that the inputs a function receives are sane.
Let’s start with unit testing.
12.1 Unit testing
Unit testing is the testing of units. What’s a unit? Functions are units! We actually already encountered one unit test before, in the save_data.Rmd script:
```{r tests-clean_flat_data}
# We now need to check if we have them all in the data.
# The test needs to be self-contained, hence
# why we need to redefine the required variables:
former_communes <- get_former_communes()
current_communes <- get_current_communes()
communes <- get_test_communes(
former_communes,
current_communes
)
raw_data <- get_raw_data(url = "https://is.gd/1vvBAc")
flat_data <- clean_raw_data(raw_data)
testthat::expect_true(
all(communes %in% unique(flat_data$locality))
)
```When using {fusen}, a unit test should be a self-contained chunk that can be executed completely independently. This is why in this chunk we re-created the different variables that were needed, communes and flat_data. If you were developing the package without {fusen}, you would need to do the same, so don’t think that this is somehow a limitation of {fusen}.
The test above ensures that we find all the former and current communes of Luxembourg in our dataset. Let me explain again why we want to write such a test down in a script and not simply try it out in our console “manually” to check if the code works.
For this test to pass, a lot of moving pieces have to fall together. If anything changes, be it because you changed something in either get_raw_data() or clean_raw_data() or because something changed with the Wikipedia tables you scraped, this test will not pass. And you should be made aware of failures as soon as possible! Also, this test ensures that when the data gets updated, you are certain that if you use the code in save_data.Rmd you will get a new dataset that is likely correct, even if new communes merge. And mergers will happen around 2024 by the way, the communes of Groussbous and Wal will merge, and the communes of Bous and Waldbredimus as well. So you need to make sure that when this happens, your code knows how to handle this, or at least returns an error as early as possible.
Ideally, you need to test every function that you wrote, but sometimes that’s not really possible, either due to lack of time, or because the function is quite trivial, so maybe no test is warranted. But be careful what you consider trivial though, I have personally been bitten in the past by “trivially” simple functions! For example, a function like this one:
```{r function-make_commune_level_data}
#' make_commune_level_data Makes the final data at commune level
#'
#' @param flat_data Flat data df as returned by clean_flat_data()
#' @importFrom dplyr filter
#' @return A data frame
#' @export
make_commune_level_data <- function(flat_data){
flat_data |>
filter(!grepl("nationale|offres", locality),
!is.na(locality))
}
```might not need to be unit-tested. An assertion, which we will learn about in the next section, is likely better suited to the above function. However, as functions become more complex, unit tests are highly recommended. This is because it can become very difficult to make sure that changing some part of the function somewhere does not affect some other part. This is where writing several unit tests can be useful. As long as all unit tests keep succeeding (or passing) you are somewhat sure that what you’re doing is not breaking stuff. And unit tests are especially useful when collaborating using trunk-based development! As the project leader, you could for example refuse to merge changes that break unit tests.
Before continuing, let’s rewrite the test we have already. While it is fully working, I didn’t really write it in the canonical form. Inside dev/save_data.Rmd, change the code of the test to the following:
```{r tests-clean_flat_data}
# We now need to check if we have them all in the data.
# The test needs to be self-contained, hence
# why we need to redefine the required variables:
former_communes <- get_former_communes()
current_communes <- get_current_communes()
communes <- get_test_communes(
former_communes,
current_communes
)
raw_data <- get_raw_data(url = "https://is.gd/1vvBAc")
flat_data <- clean_raw_data(raw_data)
test_that("Check if all communes are accounted for", {
expect_true(
all(communes %in% unique(flat_data$locality))
)
})
```The only difference is that instead of calling expect_true() directly, I wrapped this call inside test_that(). This way, I can add a description to the test. This is useful if the test fails.
Save dev/save_data.Rmd and go back to 0-dev_history.Rmd to inflate save_data.Rmd again. Everything should work without problems.
If the test fails, you get an informative message. To illustrate, I’ve added a typo in the test and inflated save_data.Rmd. Because tests always run when a fusen-package gets inflated, this test failed and here is the output:
══ Failed tests ════════════════════════════════════════════════════════════════
── Error ('test-get_raw_data.R:18'): Check if all communes are accounted for ───
Error in `communs %in% unique(flat_data$locality)`: object 'communs' not found
Backtrace:
▆
1. ├─testthat::expect_true(all(communs %in% unique(flat_data$locality)))
at test-get_raw_data.R:18:2
2. │ └─testthat::quasi_label(enquo(object), label, arg = "object")
3. │ └─rlang::eval_bare(expr, quo_get_env(quo))
4. └─communs %in% unique(flat_data$locality)
[ FAIL 1 | WARN 2 | SKIP 0 | PASS 0 ]
Error: Test failures
Execution haltedThe file test-get_raw_data.R contains our test, generated by inflating save_data.Rmd. You can find it under the tests/testthat/ folder of your inflated package. You can also see the description that we’ve added, which helps us find the test that failed. In cases like this, you should go back to the function that makes the test fail and correct it, until the test passes. You should also make sure that everything is alright with the test itself. If there really is a typo in the test, you should of course correct the test (in dev/save_data.Rmd, not in tests/testthat/)!
Now, let’s add a unit test to another function, get_laspeyeres(). This function seems to me like a good candidate for testing, as it is not that trivial.
Let’s try with something simple. get_laspeyeres() expects either commune_level_data or country_level_data. What happens if we provide another dataset? The function very likely returns an error. So let’s test for this. Go back to the save_data.Rmd file and add the following, under the function definition of get_laspeyeres():
```{r tests-get_laspeyeres}
test_that("Wrong data", {
expect_error(
get_laspeyeres(mtcars)
)
})
```Since we expect an error, we used expect_error(), which succeeds if the code fails! If you’re confused, no worries, we’ve all been there. But let’s think about it: what would you want to happen if you provided a wrong data set? Surely, you’d like for the function to scream an error at you, and not somehow do something and return something. So testing that functions fail when they should is actually quite important as well. Let’s add another, similar, test:
```{r tests-get_laspeyeres}
test_that("Wrong data", {
expect_error(
get_laspeyeres(mtcars)
)
})
test_that("Empty data", {
expect_error(
# this subsetting results in an empty dataset
get_laspeyeres(subset(mtcars, am == 2))
)
})
```This second test checks what happens if we provide an empty dataset. This should not happen, but hey, it’s always a good idea to see what could happen. Here we also expect an error, so we use expect_error() as well. Inflating save_data.Rmd runs the tests again, and all of them succeed.
Now, I know what you’re thinking. Probably something along the lines of “Bruno, you told me that making my projects reproducible and reliable and robust would not take much more time than what I was already doing before. This certainly doesn’t feel like it!”, to which I answer that your feelings on the issue are wrong. It may not feel like it, but doing this does two things:
- It ultimately saves you time. You typed the test once, and can now rerun it automatically every time you inflate the
.Rmdfiles. You don’t need to remember to test the code, and don’t need to remember how to test the code. - This saves you a lot of headaches. You don’t have to live in fear that you might forget to test the code, or forget how to test the code. You wrote the tests down, and now you’re free to concentrate on adding features or using the existing code knowing that you can trust its outputs.
Trust the process.
Let’s go back to the two tests from before: get_laspeyeres() fails, as expected, when we provide a random dataset to it. But it would be interesting to know why it fails. Simply run get_laspeyeres(mtcars) in the console. This is what we get back:
Error in `mutate()`:
! Problem while computing `p0 = ifelse(year == "2010",
average_price_nominal_euros, NA)`.
Caused by error in `ifelse()`:
! object 'year' not found
Run `rlang::last_error()` to see where the error occurred.So the functions fails but for the wrong reason. It fails because the column year cannot be found in the data. But what if there was a column year in the data? The code would continue, but then likely fail for some other reason. It would be much safer to make it fail as soon as possible, by detecting right from the start if the provided data sets are not one of commune_level_data or country_level_data. But for this, we need assertive programming, which we will discuss in the next section. Why an assertive test and not a unit test? Because unit tests should run during development time, and assertive tests run at run-time (when the function is executed). So in this case, we want the input to get checked at run-time. In the next section, we will be changing the function to fail when the right datasets are not provided, but our unit test will not need to change; the function still fails, but this time it’ll be for the right reasons.
This is another advantage of writing tests: it forces you to think about what you’re doing. The simple act of thinking and writing tests very often improves your code quite a lot, and not just from a pure algorithmic perspective, but also from a user experience perspective. Writing these tests made us think about the failure of our function when users provide a wrong dataset and made us realise that it would be much better for users if the returned error message is something along the lines of “Wrong dataset, please provide either commune_level_data or country_level_data”.
Let’s continue with testing get_laspeyeres(). It would be nice to see if the function actually does what it’s supposed to do correctly. For this, we need to start from an input, and then create the expected output. It doesn’t matter how you create this output, what matters is that you make absolutely sure that it is correct, and then, never touch it ever again. Let’s call this output the “truth”. Then, you provide get_laspeyeres() with this input and save the output that get_laspeyeres() generates. You then compare the “truth” to this output. If everything matches, congratulations, your function produces the right output.
So let’s start. Remember that unit tests should be self-contained, so I’m going to create the input dataset and the expected data set (what I called the “truth”) in the test itself. This is the code I’m going to use to create the mock, input dataset:
This creates a data frame with two years, two communes and some mock prices. Now, I need to create the output. I start from the input, and add the columns that get computed by running get_laspeyeres() myself, “by hand”. Remember, you need to make sure that these results are correct!
expected_df <- input_df
# p0 should be always equal to the value in the first year
expected_df$p0 <- c(234, 234, 560, 560)
expected_df$p0_m2 <- c(23, 23, 56, 56)
# pl should be equal to the price divided by p0
expected_df$pl <-
expected_df$average_price_nominal_euros/
expected_df$p0 * 100
expected_df$pl_m2 <-
expected_df$average_price_m2_nominal_euros/
expected_df$p0_m2 * 100If you look at each line, you see that this is exactly what get_laspeyeres() does. We can inspect the results and maybe even verify the value of each cell using a pocket calculator. It doesn’t matter, what’s important is that expected_df is correct and saved. This is what the full test looks like:
```{r, eval = F}
test_that("get_laspeyeres() produces correct results", {
input_df <- expand.grid(
list("year" = c(2010, 2011),
"locality" = c("Bascharage", "Luxembourg"))
)
input_df$n_offers <- c(123, 101, 1230, 1010)
input_df$average_price_nominal_euros <- c(234, 345, 560, 670)
input_df$average_price_m2_nominal_euros <- c(23, 34, 56, 67)
expected_df <- input_df
# p0 should be always equal to the value in the first year
expected_df$p0 <- c(234, 234, 560, 560)
expected_df$p0_m2 <- c(23, 23, 56, 56)
# pl should be equal to the price divided by p0
expected_df$pl <- expected_df$average_price_nominal_euros / expected_df$p0 * 100
expected_df$pl_m2 <- expected_df$average_price_m2_nominal_euros / expected_df$p0_m2 * 100
expect_equivalent(
expected_df, get_laspeyeres(input_df)
)
})
```Notice that I’ve used expect_equivalent() and not expect_equal() to check if expected_df is equal to the output of get_laspeyeres(input_df). This is because expected_df is of class data.frame, while get_laspeyeres() outputs a tibble. So if you use expect_equal() the test would not pass, because the classes of both objects are not strictly equal. Sometimes, this level of strictness is required, but not always, as is the case here.
Once again, inflate save_data.Rmd. This will run the tests, and if everything went well, you should end up, again, with a functioning package. I highly advise that you consult {testthat}’s documentation to learn about all the other functions that you can use for writing unit tests.
If you’ve managed to write the unit tests and inflate the package successfully, then let’s move on to assertive programming.
12.2 Assertive programming
Remember in Chapter 6, where I discussed safe functions? As a refresher, here’s the nchar() function, providing a correct output when the input is a character:
nchar("100000000")[1] 9and here is nchar() providing a surprising result when the input is a number:
nchar(100000000)[1] 5This is because 100000000 gets converted to 1e+08 and then this gets converted into the string "1e+08" which is 5 characters long. So in that section, I suggested defining your own nchar2() that makes sure that the provided input is a character:
nchar2 <- function(x, result = 0){
if(!isTRUE(is.character(x))){
stop(paste0("x should be of type 'character', but is of type '",
typeof(x), "' instead."))
} else if(x == ""){
result
} else {
result <- result + 1
split_x <- strsplit(x, split = "")[[1]]
nchar2(paste0(split_x[-1],
collapse = ""), result)
}
}This now returns an error if the input is a number, instead of doing all these silent conversions. The technique we have used here is what we call assertive programming. stop() and stopifnot() are functions included with R that can be used for assertive programming. Here is an example using stopifnot():
nchar3 <- function(x, result = 0){
stopifnot("Input x must be a character" =
isTRUE(is.character(x)))
if(x == ""){
result
} else {
result <- result + 1
split_x <- strsplit(x, split = "")[[1]]
nchar3(paste0(split_x[-1],
collapse = ""), result)
}
}If we go back to get_laspeyeres(), we should be using assertive programming to make sure that the provided datasets are one of commune_level_data or country_level_data. This is how we could rewrite the function:
get_laspeyeres <- function(dataset){
which_dataset <- deparse(substitute(dataset))
stopifnot("dataset must be one of `commune_level_data`
or `country_level_data`" =
(which_dataset %in% c(
"commune_level_data",
"country_level_data")))
group_var <- if(grepl("commune", which_dataset)){
quo(locality)
} else {
NULL
}
dataset |>
group_by(!!group_var) |>
mutate(
p0 = ifelse(
year == "2010",
average_price_nominal_euros,
NA)
) |>
fill(p0, .direction = "down") |>
mutate(
p0_m2 = ifelse(
year == "2010",
average_price_m2_nominal_euros,
NA)
) |>
fill(p0_m2, .direction = "down") |>
ungroup() |>
mutate(
pl = average_price_nominal_euros/p0*100,
pl_m2 = average_price_m2_nominal_euros/p0_m2*100)
}We can now also edit the unit test from before, the one where we provide the wrong data. With this new specification of the function, this unit test would still pass (the function returns an error), as expected, but for the wrong reason. We now want to make sure that it fails for the right reason, in other words, that it fails not because no year column is found, but because the provided data set is neither commune_level_data nor country_level_data, so for this we change the unit tests like this:
test_that("Wrong data", {
expect_error(
get_laspeyeres(mtcars),
regexp = "dataset must be one of"
)
})I use the regexp argument of expect_error to enter a regular expression that matches the error message. So the string “dataset must be one of” will match the message returned by the error, and if they match (remember, the provided string is a regular expression), then I know I get the correct error. Here is what happens if I use the wrong message as the regex argument:
══ Failed tests ════════════════════════════════════════════════════════════════
── Failure ('test-get_laspeyeres.R:6'): Wrong data ─────────────────────────────
`get_laspeyeres(mtcars)` threw an error with unexpected message.
Expected match: "message is wrong"
Actual message: "dataset must be one of `commune_level_data`
or `country_level_data`"So now, not only does our function fail for the right reasons, our test is able to tell us that as well!
Before inflating to run these tests, you should also change the test titled “get_laspeyeres() provides correct answers”. This is because the name of the input dataset used for the test is input_df. So if you leave it like this, the assertion that we’ve included in the function will make this test fail. So change this test by simply saving input_df as commune_level_data:
# rename data to make assertion pass
commune_level_data <- input_df
expect_equivalent(
expected_df, get_laspeyeres(commune_level_data)
)if you forget to do this, don’t worry, the unit test would not fail to remind you!
Go back to 0-dev_history.Rmd and inflate the file again to update it. Everything should work without any issues. If not, take the time to make the unit tests pass and inflate the package successfully!
Something else that is well-suited for assertive programming is checking whether the provided inputs are of the right class:
any_function <- function(dataset){
stopifnot("`dataset` must be a data frame" =
inherits(dataset, "data.frame"))
print("No problem")
}This will succeed:
any_function(mtcars)[1] "No problem"But this will fail:
any_function("this is not a data frame")Error in any_function("this is not a data frame") :
`dataset` must be a data frameinherits() checks if an object inherits from a certain class. So for example, a tibble or a data.table that are classes that are defined by inheriting attributes from the data.frame class, will also successfully pass the test above. You can be as strict as you need: for example, do you need any type of number? You could do the following:
inherits(2, "numeric")[1] TRUEBut do you actually need integers, and want to force this? Then you could be stricter in your assertion:
inherits(2, "integer")[1] FALSEIf you want the above to evaluate to TRUE, an integer must be provided:
inherits(2L, "integer")[1] TRUEDo you want, for some reason, that your functions only accept tibbles and not data.frames? Be as strict as you need. This will succeed:
inherits(tibble::as_tibble(mtcars), "tbl_df")[1] TRUEThis will fail:
inherits(mtcars, "tbl_df")[1] FALSEYou could also use more complex assertions. For example, suppose that you need to clean data using many functions, with several filters. Something could go wrong in any of these functions for a variety of reasons. So each of these functions could test if all the individuals are still in the data, and that you didn’t remove any of them by mistake. A test like this could make sure that each level of the variable am are still in the data:
summary_stats <- function(dataframe, var){
stopifnot("Some individuals are missing!" =
all((unique(dataframe[[var]])) %in% c(0,1)))
# and then some computations here
}Now, when running summary_stats(mtcars, "am"), if somehow the level “1” or “0” is missing from mtcars, the function would throw an error.
There are several packages for assertive programming that you might want to check out:
I won’t discuss any of them; what’s important is for you to know that assertive programming is something that is useful and that you should add to your toolbox.
12.3 Test-driven development
Test-driven development, or TDD, is the programming paradigm in which instead of writing a function and then several tests to ensure that the code is working as expected, you start by writing tests, and then the function. Of course, since there is no function to test, these tests will all obviously fail at first. But the goal is to then write a function such that the tests pass.
TDD is interesting in at least two scenarios:
- You want to write a function, but don’t know exactly where to start. Maybe it’s a very complex function. So writing tests can help you think about it, and already fix certain properties that this function should have.
- You use the tests as a way to write requirements for a code-base. This can be useful when working in a team, and you don’t want to “waste” time writing requirements, so instead you write tests that describe how the function should work, what type of inputs get accepted, how its output looks like… Careful though, because a “smart” programmer could write code that passes the tests but doesn’t actually do anything otherwise useful.
I tend to use TDD when I need to write a function but don’t quite know where to start. I start by writing the most basic tests and make them ever more complicated. At some point, I start having an idea for the function’s implementation and have a go at it.
Some programmers only do TDD; so they start by writing many, many tests, and then only start writing their functions. Personally, I think that this is also not ideal, because you could waste a lot of time writing meaningless tests.
12.4 Code coverage
It is useful to have an idea of which functions are tested and which are not, but also how much of a function is being tested. For example, suppose that you have an if...else... clause somewhere in a function. Did you write a test for each of the outcomes of this clause? Maybe you only wrote a test when this clause evaluates to TRUE, but forgot to write a test for the case it is FALSE.
The packages {covr} allows you to track the test coverage of your package. Install {covr} and run report() in the console to get the results:
covr::report()This should open a tab in your web browser with some statistics. You can click on the individual scripts to see the source code of your functions: each line that is highlighted in green represents a line that is being tested, and lines in red are lines that are not being tested:
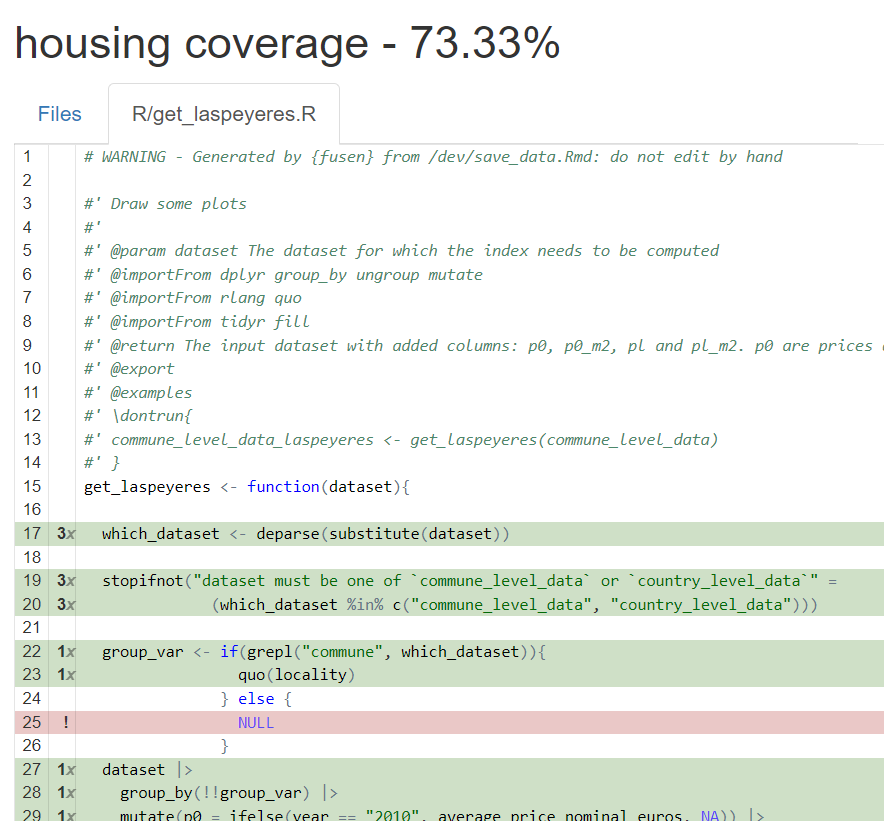
You could strive to get 100% coverage by painting all the lines green (by writing unit tests that test these lines). But in practice, it is not always so easy to get 100% coverage, so don’t fret if you don’t achieve perfection.
If you’re working on a server (and thus do not have access to a graphical user interface) you can instead use the covr::package_coverage() function which provides you with the following results (printed in the console):
housing Coverage: 73.33%
R/get_laspeyeres.R: 57.14%
R/get_raw_data.R: 80.65%The percentage represents the share of lines of code that are tested by our unit tests. We see that the share of lines being tested in get_laspeyeres.R is 57%: this is because the script get_laspeyeres.R contains two functions, get_laspeyeres() and make_plot(). We do not test make_plot() at all, hence why the percentage is so low. We could move make_plot() to another script by simply putting the function under a level two header in the original .Rmd file and then inflating again. But in any case, this would not improve the overall coverage of the package; we would ideally need to write a test for make_plot(). This is left as an exercise to the reader.
12.5 Conclusion
Testing is crucial and useful. Not just because it gives you peace of mind but also because writing tests forces you to think about your code, by putting yourself in the shoes of your users (which include future you as well). In most cases, it is even something that you’ve been doing but perhaps not as systematically as you should.
There really is no other way to say this: you need to consider writing tests as an integral part of the project, and need to take the required time it takes to write them into account when planning projects. But keep in mind that writing them makes you gain a lot of time in the long run, so actually, you might even be faster by writing tests! Tests also allow you to immediately see where something went wrong, when something goes wrong. So tests save you time here as well. Without tests, when something goes wrong, you have a hard time finding where the bug comes from, and end up wasting precious time. And worse, sometimes things go wrong and break, but silently. You still get an output that may look ok at first glance, and only realise something is wrong way too late. Testing helps to avoid such situations.
So remember: it might feel like packaging your code and writing tests for it takes time, but you’re actually already doing it, but non-systematically and manually and it ends up saving you time in the long run instead. Testing also helps with developing complex functions.
The tools I’ve shown you in this and the previous chapter are probably the fastest, easiest options to go from your analysis to a documented and tested package in a matter of hours. The benefits these provide however are measured in days of work.