make_plot <- function(country_level_data,
commune_level_data,
commune){
filtered_data <- commune_level_data %>%
filter(locality == commune)
data_to_plot <- bind_rows(
country_level_data,
filtered_data
)
ggplot(data_to_plot) +
geom_line(aes(y = pl_m2,
x = year,
group = locality,
colour = locality))
}5 Collaborating using Trunk-based development
As already mentioned several times, there are two ways of collaborating with Git (and Github): either as a team, or as an external dev (external, as in, not part of the development team of a given project). External contributors can only contribute code to public repositories, and the project owners can either accept or refuse the patches.
We are going to learn about these two ways of collaborating. Let’s first focus on collaboration within a team.
5.1 Collaborating as a team
5.1.1 TBD basics
Remember the issue we opened and assigned to Bruno? Bruno will now take care of this issue by adding a Readme file. This will also be the opportunity to introduce trunk-based development. The idea of trunk-based development is simple; team members should work on separate branches to add features or fix bugs, and then merge their branch to the “trunk” (in our case the master branch) to add their changes back to the main codebase. And this process should happen quickly, ideally every day, or as soon as some code is ready. When a lot of work accumulates in a branch for several days or weeks, merging it back to the master branch can be very painful. So by working in short-lived branches, if conflicts arise, they can be dealt with quickly. This also makes code review much easier, because the reviewer only needs to review little bits of code at a time. If instead long-lived branches with a lot of code changes get merged, reviewing all the changes and solving the conflicts that could arise would be a lot of work. To avoid this, it is best to merge every day or each time a piece of code is added, and, very importantly, this code does not break the whole project (we will be using unit tests for this later).
So in summary: to avoid a lot of pain by merging branches that moved away too much from the trunk, we will create branches, add our code, and merge them to the trunk as soon as possible. As soon as possible can mean several things, but usually this means as soon as a feature was added, a bug was fixed, or as soon as we added some code that does not break the whole project, even if the feature we wanted to add is not done yet. The philosophy is that if merging fails, it should fail as early as possible. Early failures are easy to deal with.
Our aim should be to provide a functioning project to anyone cloning the master branch anytime (but still offer a simple way to install a point release of the project).
So, back to our issue. First, Bruno needs to clone the repository:
bruno@computer ➤ git clone git@github.com:rap4all/housing.gitTo add the feature, Bruno will now create a new branch by using the git checkout command with the -b flag:
bruno@computer ➤ git checkout -b "add_readme"The project automatically switches to the new branch:
Switched to a new branch 'add_readme'We can also run git status to double-check:
bruno@computer ➤ git statusOn branch add_readme
nothing to commit, working tree cleanBruno adds a file called README.md and adds the following text to it:
# Housing data for Luxembourg
These scripts for the R programming language download nominal
housing prices from the *Observatoire de l'Habitat* and
tidy them up into a flat data frame.
- save_data.R: downloads, cleans, and creates data frames from the data
- analysis.R: creates plots of the dataLet’s save this and run git status to see what happened:
bruno@computer ➤ git statusGit tells Bruno that the README.md file is not being tracked:
On branch add_readme
Untracked files:
(use "git add <file>..." to include in what will be committed)
README.md
nothing added to commit but untracked files present (use "git add" to track)So next Bruno is going to track it and push the changes. Also, Bruno is going to use a neat trick when pushing: because Bruno is working on fixing an issue, it would be great if he could close it as he pushes the fix. This is possible by referencing the issue number in the commit message:
bruno@computer ➤ git add .
bruno@computer ➤ git commit -m "fixed #1"#1 refers to the number of the issue (it’s the first issue that was opened in the repository). So by referencing this issue with its number in the commit message and pushing, the issue gets automatically closed when Bruno pushes:
bruno@computer ➤ git push origin add_readmeAs you can see from the command above, Bruno pushes to “add_readme”, the branch he opened to solve the issue, not “master”. If he tried to push to “master” a message saying that “master” is up-to-date would get printed. Let’s see the output of pushing to “add_readme”:
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 12 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 501 bytes | 501.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
remote:
remote: Create a pull request for 'add_readme' on GitHub by visiting:
remote: https://github.com/rap4all/housing/pull/new/add_readme
remote:
To github.com:rap4all/housing.git
* [new branch] add_readme -> add_readmeGit tells us that Bruno now needs to create a pull request. What is that? Well, if we want to merge our branch back into the trunk, we need to do so by using a pull request. Let’s see what Bruno sees on Github:
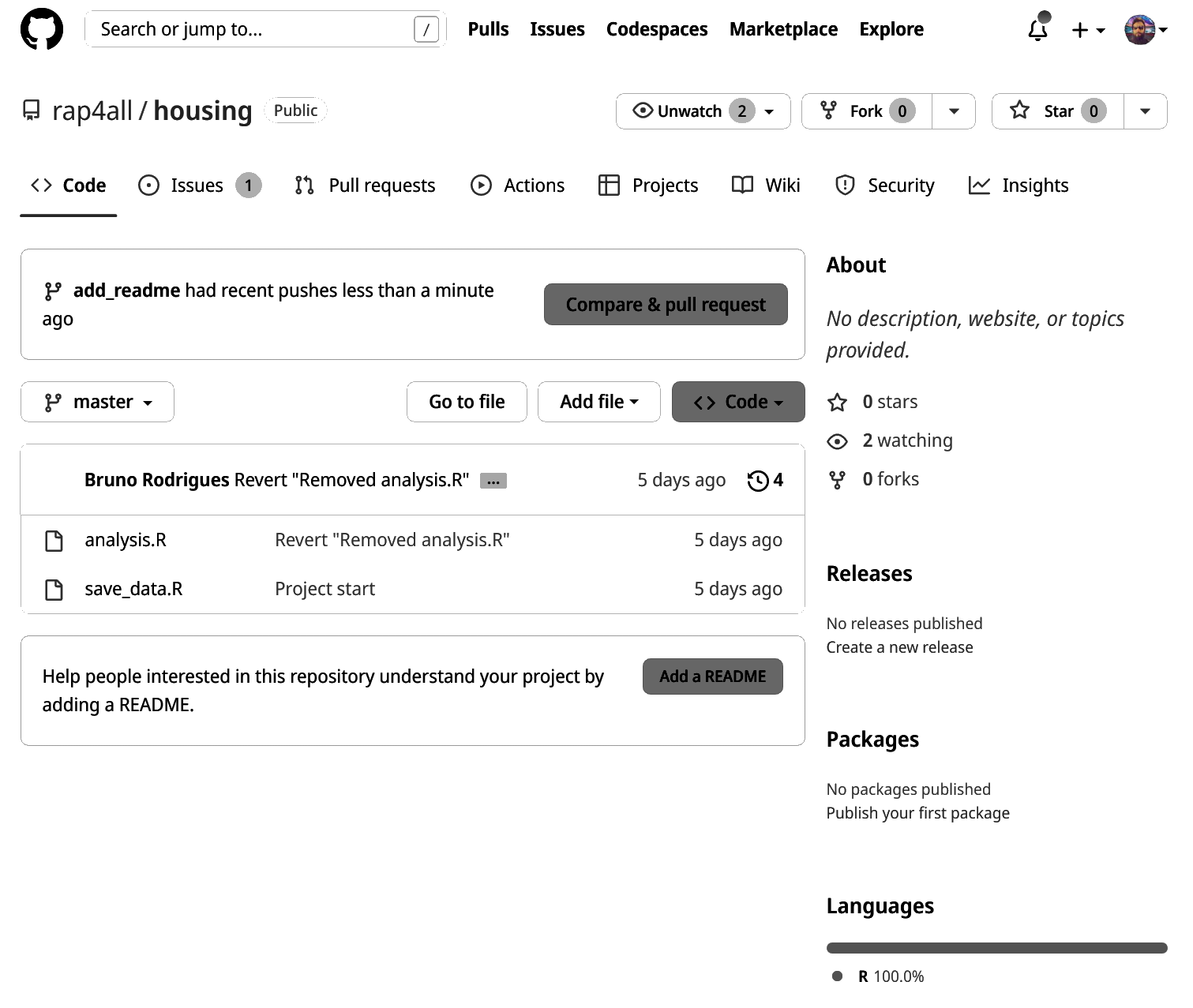
Bruno can now decide to continue working on this branch, or, since the purpose of this branch was only to add the Readme file, decide instead to do a pull request.
By clicking on the “Compare & pull request” button Bruno now sees this:
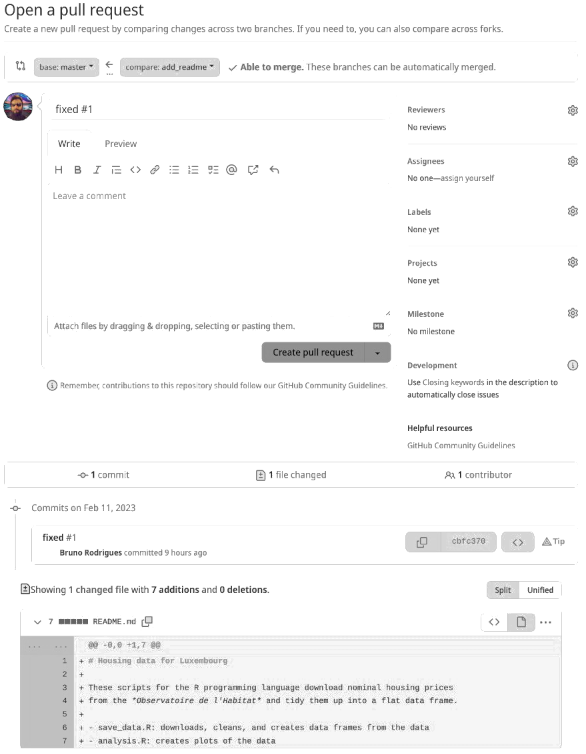
Bruno can leave a comment, and see what changed (in this case, a single file was added) and most importantly, add a reviewer if needed:
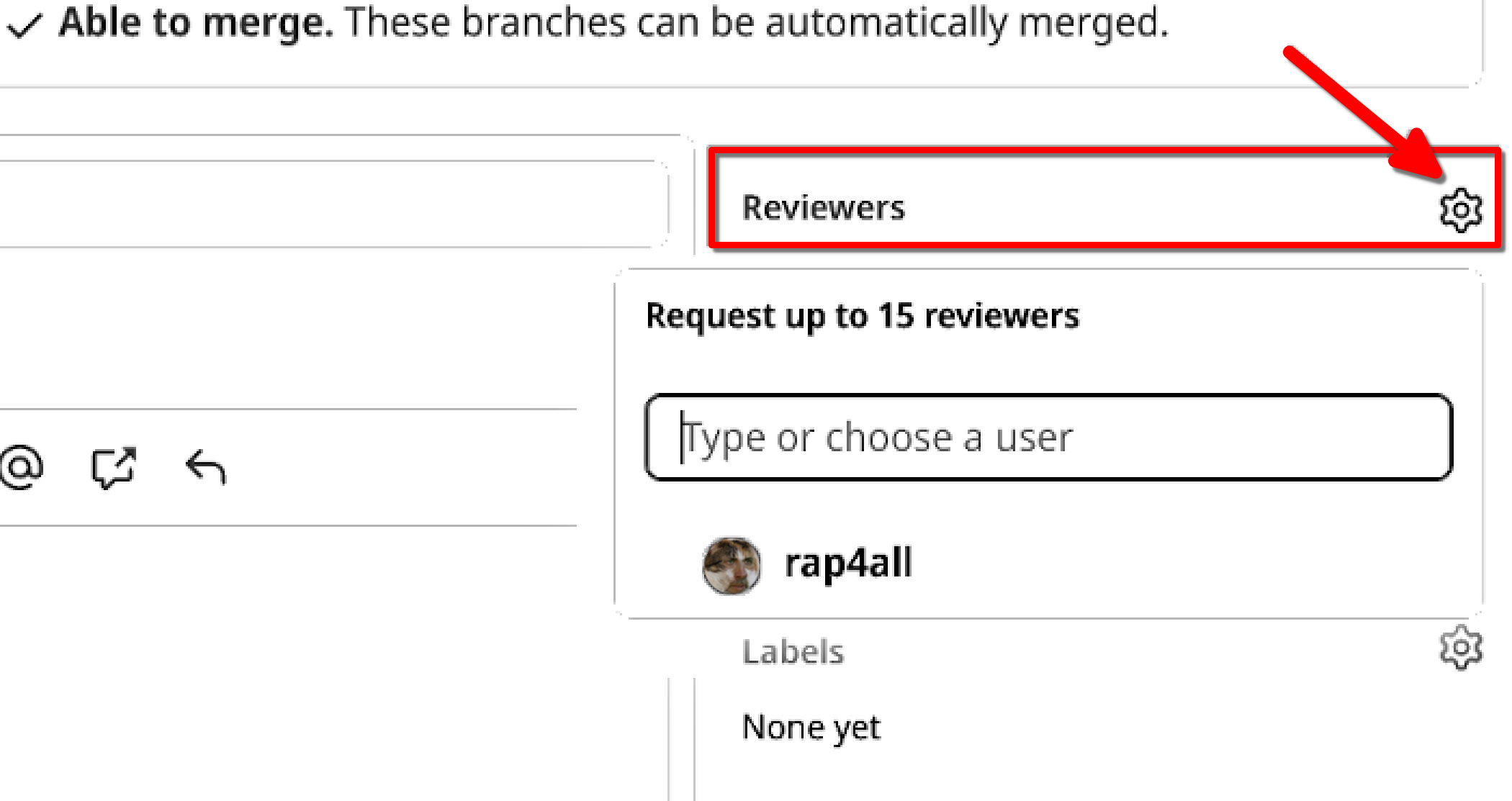
This is what Bruno sees now:
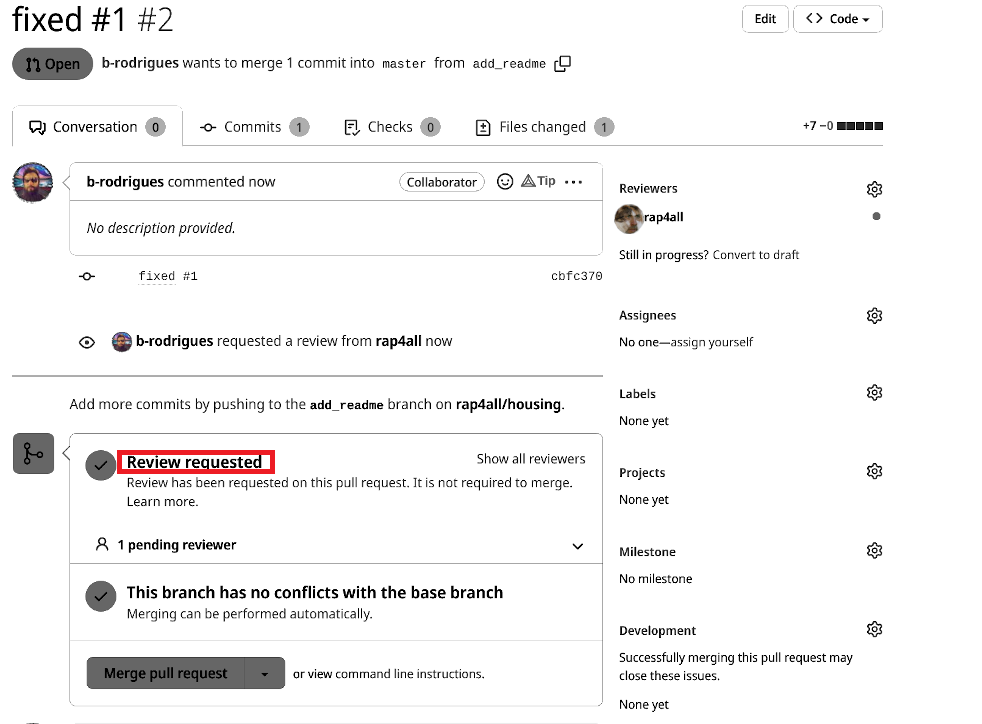
Bruno requested the review, but Github tells us that the branch can safely be merged. This is because we added a file and did not touch anything else, and no one else worked on the project while Bruno was working. So there are no risks of conflicts arising.
Let’s see what the owner now sees. The project owner should have gotten a notification to review the pull request:
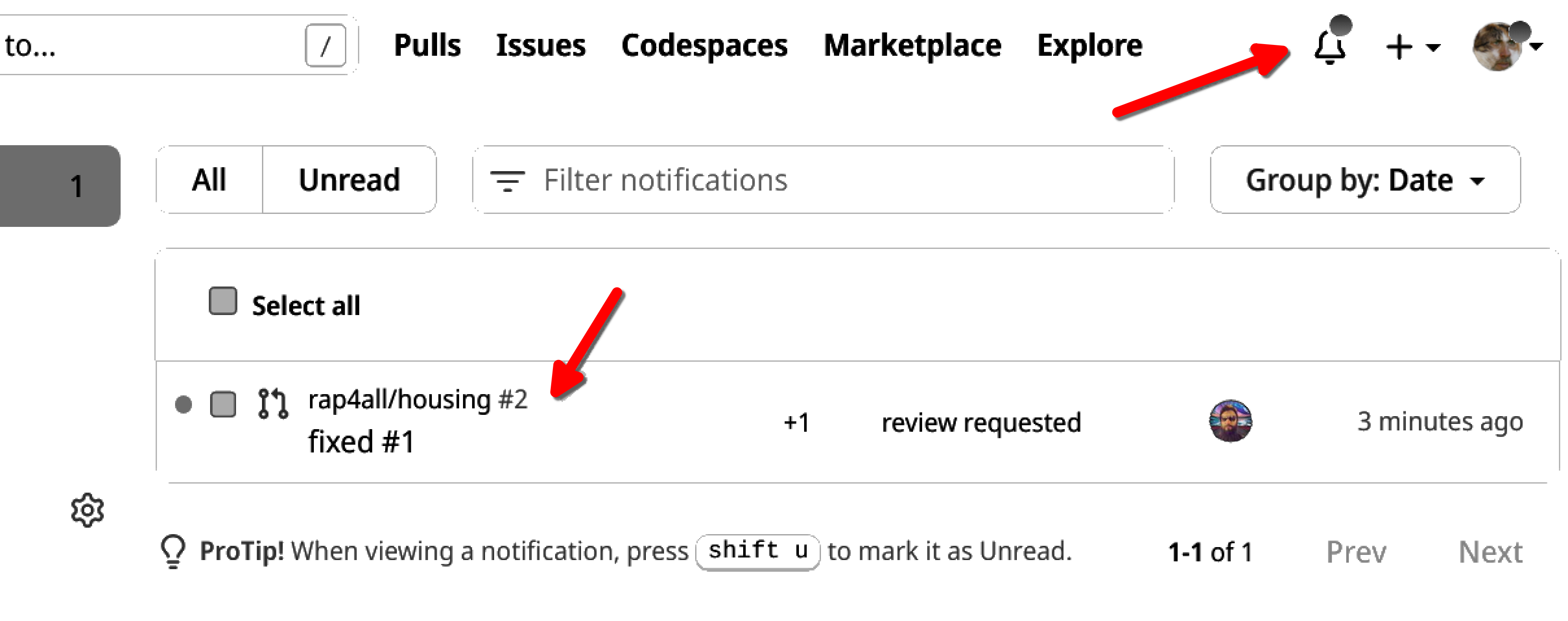
By clicking on the notification, the owner gets taken to this view:
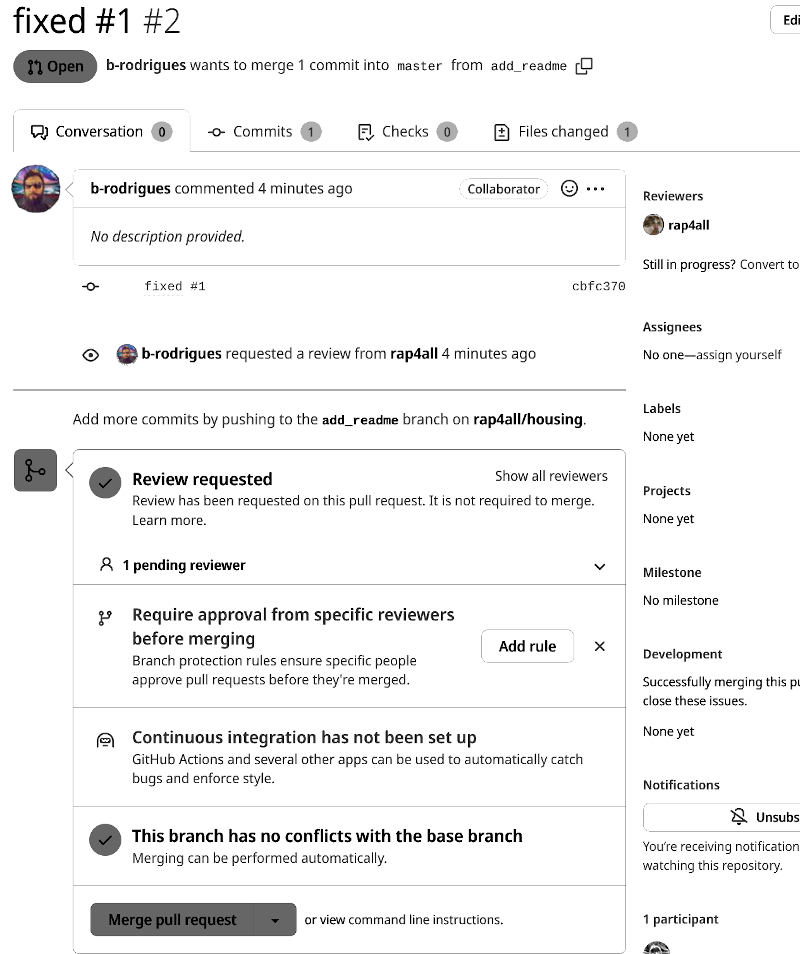
Here, the reviewer can check the commit, the files that were changed, and see if there are any conflicts between this code and the code base on the master (or trunk) branch. Github also tells us two interesting things: the owner can add a rule that states that any pull request must be approved, and also that continuous integration has not been set up (we are going to see what this means in the second part of this book).
Let’s go ahead and add a rule forcing each pull request to be approved. By clicking on “Add rule”, the following screen appears:
By clicking the first option, more sub-options appear:
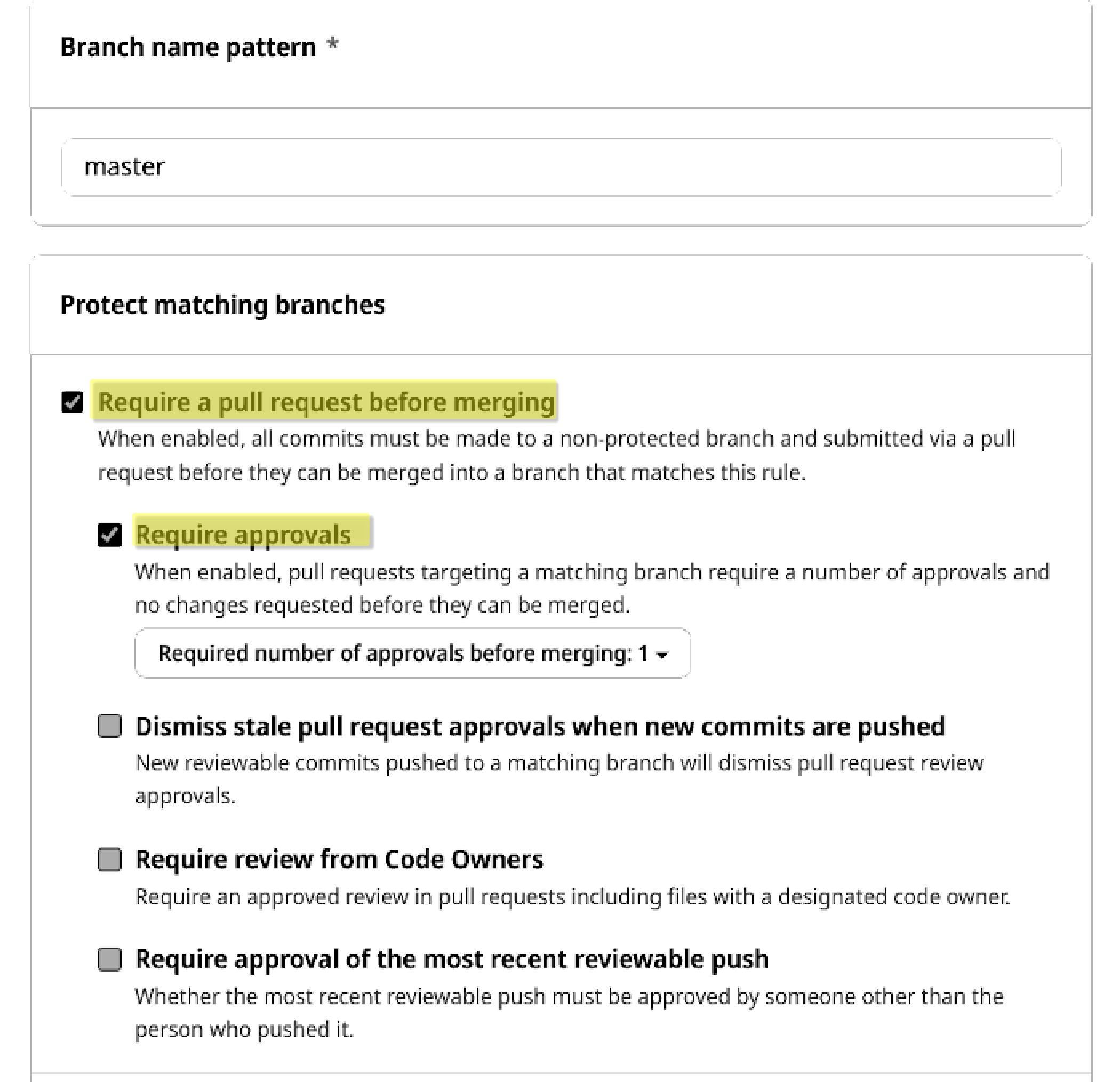
By choosing these options, the owner can basically enforce trunk-based development (well, collaborators still have to submit pull requests frequently enough though, because if they don’t, we can be in a situation where merging can be very difficult).
Let’s choose one last option: by scrolling down, it’s possible to select the option “Do not allow bypassing the above settings”. This makes sure that even administrations (the owners of the project) must abide by the same rules.
Let’s go back to the pull request. We can see now that a review is required:
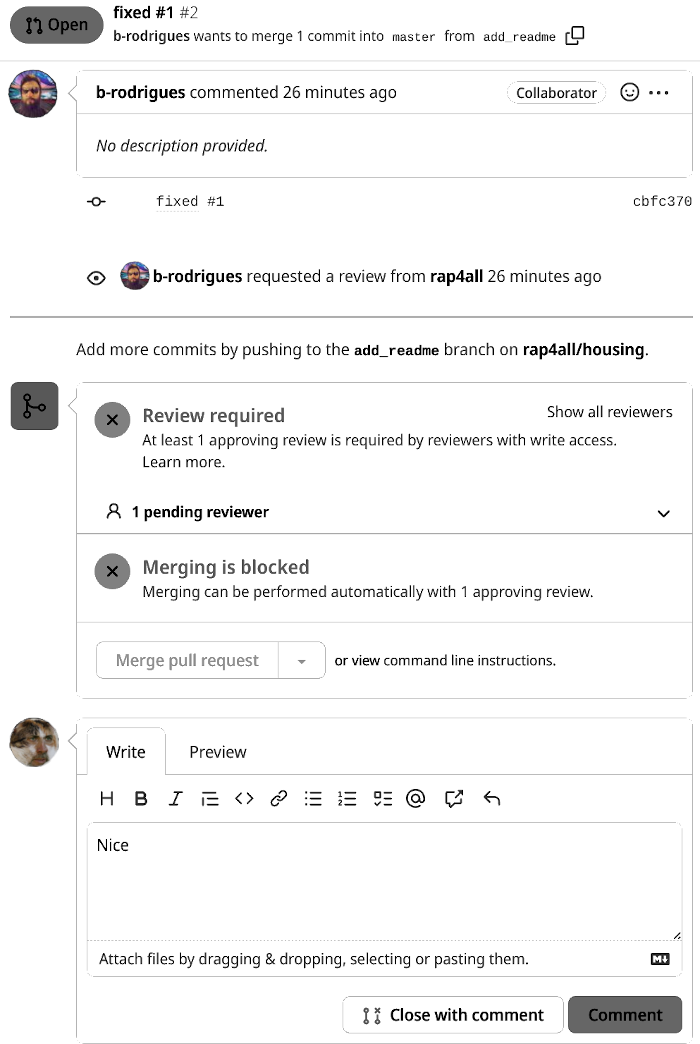
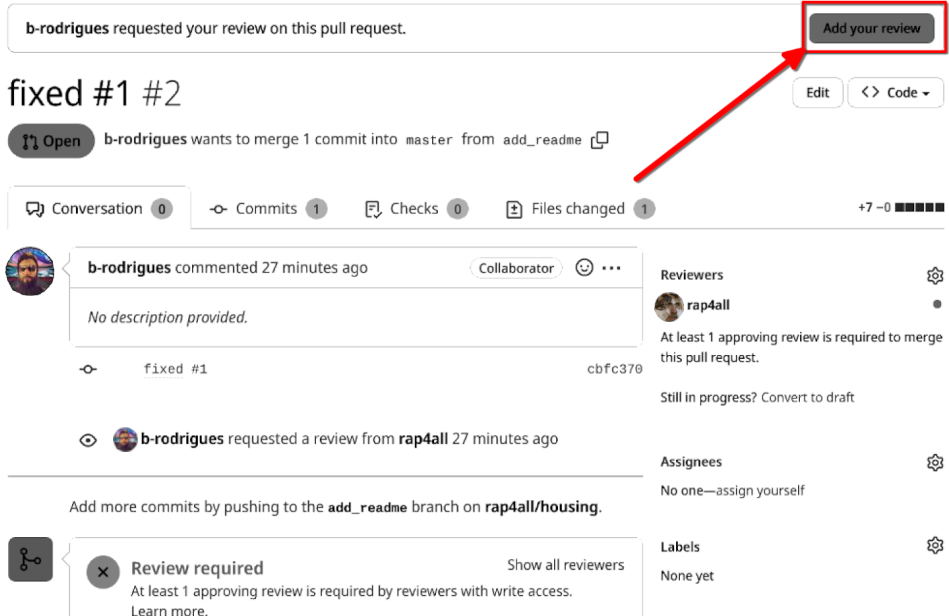
So now the owner actually has to go and see the files that were changed:
It’s possible to add comments to single lines if needed:
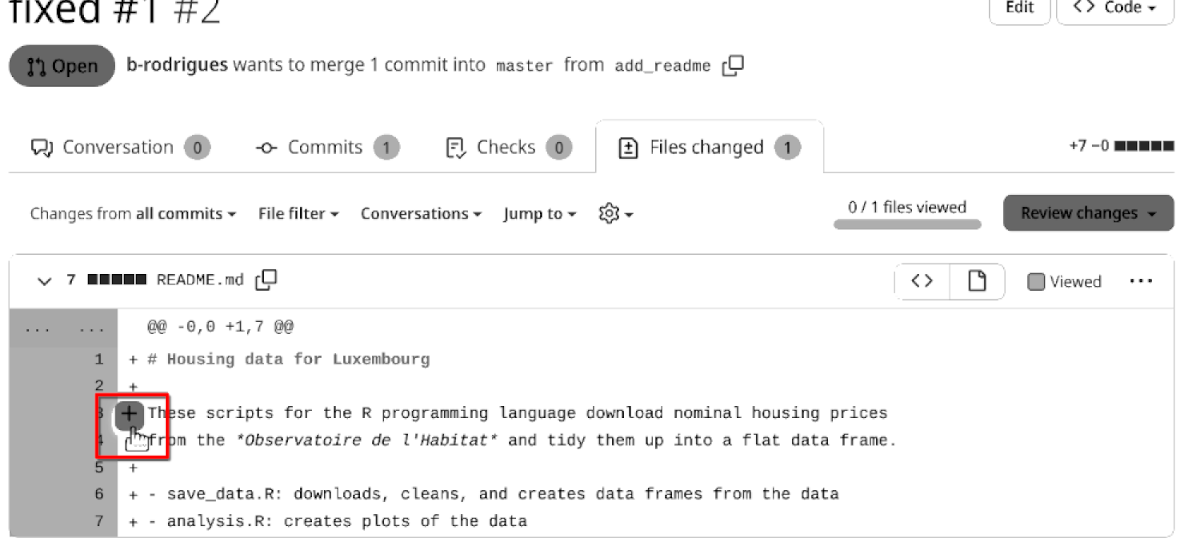
By clicking on the plus sign, a box appears and it’s possible to leave a comment. In this case, everything is fine, so the owner is going to click on the “Viewed” button:
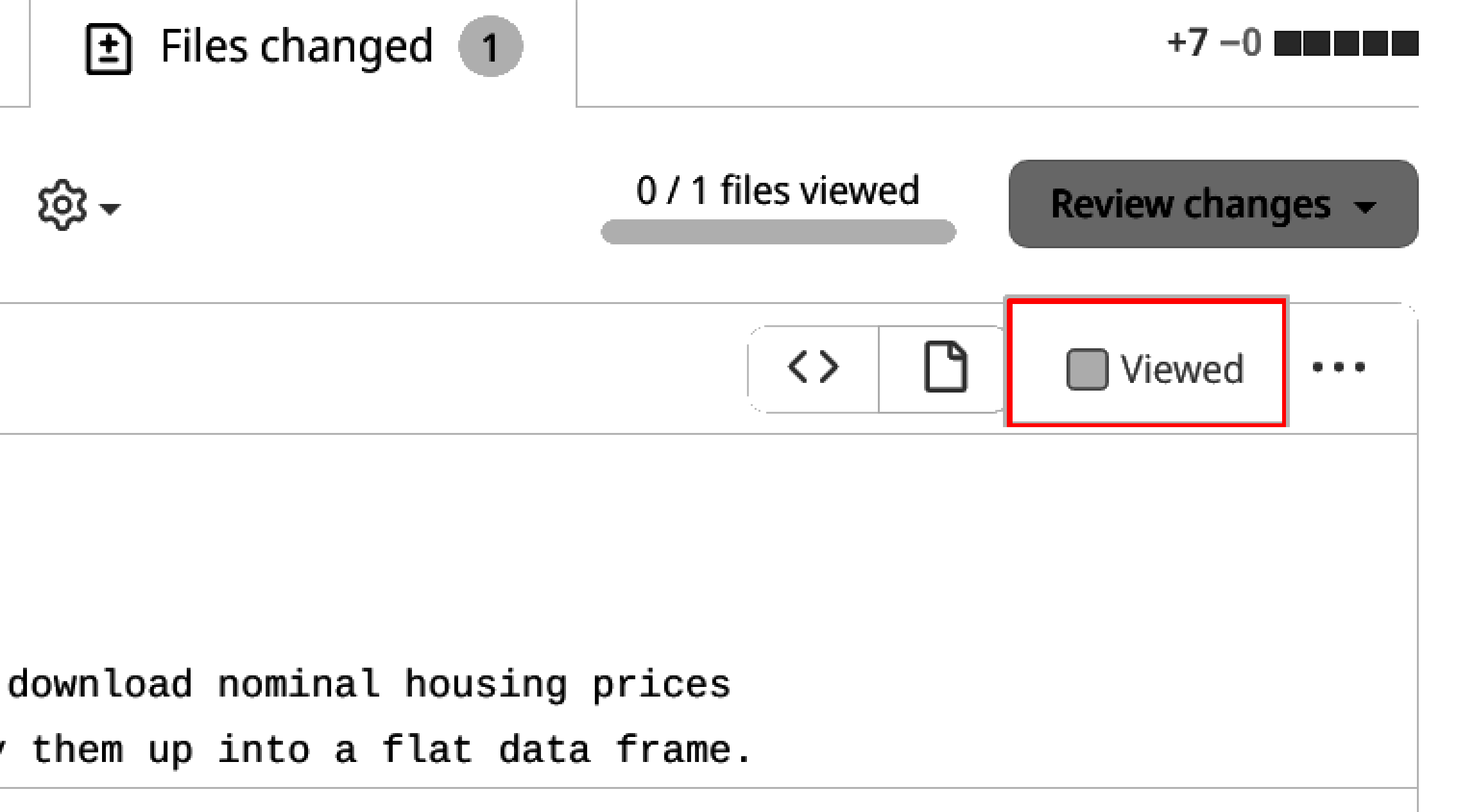
Then, by clicking on “Review changes”, it’s possible to either add a general comment, approve the pull request, or request changes that must be addressed before merging. Let’s go ahead and approve:
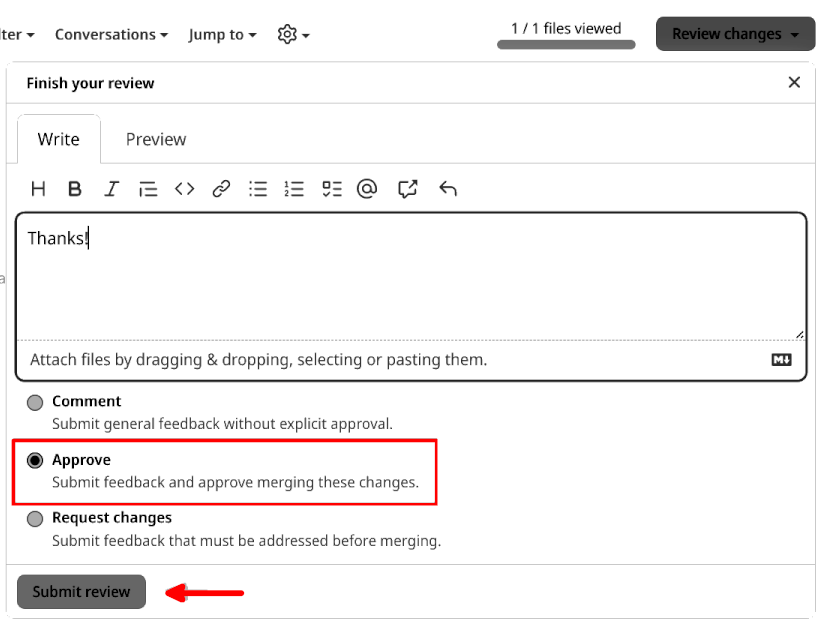
By submitting the review, the reviewer is taken back to the issue:
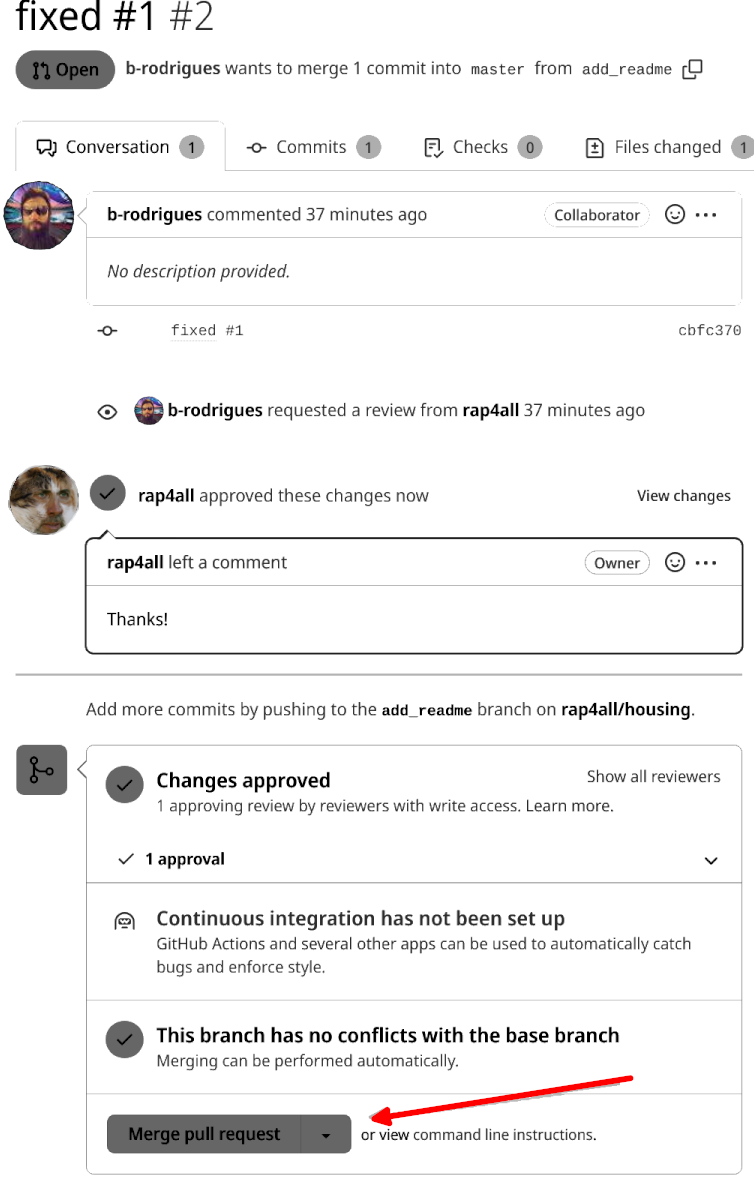
The reviewer can now merge the pull request by clicking on the “Merge pull request” button. Github even suggests we delete the branch, which has served its purpose:
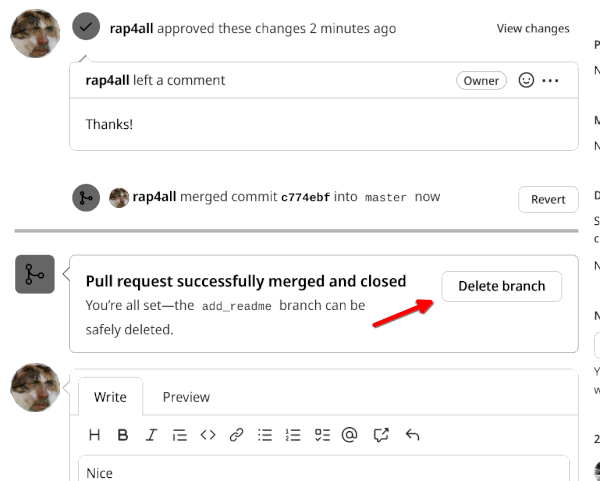
Let’s delete it (it’s always possible to restore it).
5.1.2 Handling conflicts
As mentioned in the previous chapter, Git makes it easy to handle conflicts. Well, let’s be clear; even with Git, it can sometimes be very tricky to resolve conflicts. But you should know that when solving a conflict with Git is difficult, this usually means that it would be impossible to do any other way, and would inevitably result in someone having to reconcile the files by hand. What makes handling conflicts easier with Git though, is that Git is able to tell you where you can find clashes on a per-line basis. So for instance, if you change the first ten lines of a script, and I change the next ten lines, there would be no conflict, and Git will automatically merge both our contributions into a single file. Other tools, like Dropbox, would fail in a situation like this, because these tools can only handle conflicts on a per-file basis. The same file was changed by two different persons? Regardless of where these changes happened, you now have a conflict to deal with on your hands… and worse, you don’t even know where the conflicts are in the file! You will need to scan the two resulting copies of the file by hand. Git, in the case where the same lines were changed, highlights them very clearly so that you can quickly find them and deal with the problems.
We will see all of this in the coming sections.
So how do conflicts happen? Let’s imagine the following scenario. Both Bruno and the project owner create branches, and edit the same file. Perhaps they talked over the phone and decided to add a feature or correct a bug. Perhaps they decided that it wasn’t worth opening an issue on Github and assign someone to do it. After all, they discussed this on the phone and decided that Bruno should do it. Or was it the owner who needed to solve the issue? No one remembers now. Either way, they both did, and changed the same file, so a conflict will ensue.
First, Bruno needs to switch back to the master branch on his computer:
bruno@computer ➤ git checkout masterSwitched to branch 'master'
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
(use "git pull" to update your local branch)Git tells us to update the code on our computer by running git pull. We use git push to upload code to Github, and use git pull to download code from Github. Let’s run it and see what happens:
bruno@computer ➤ git pullUpdating b7f82ee..c774ebf
Fast-forward
README.md | 7 +++++++
1 file changed, 7 insertions(+)
create mode 100644 README.mdFiles on Bruno’s computer have been updated. The owner of the project (called owner, remember?) can do the same and will see the same. Now, Bruno creates a new branch to work on the new feature:
bruno@computer ➤ git checkout -b add_cool_featureAnd the project owner also creates a new branch:
owner@localhost ➤ git checkout -b add_sweet_featureThey now edit the same file, analysis.R. Bruno added this function:
This way, Bruno could delete the repeating code and create plots like this:
lux_plot <- make_plot(country_level_data,
commune_level_data,
communes[1])
# Esch sur Alzette
esch_plot <- make_plot(country_level_data,
commune_level_data,
communes[2])
# and so on...The end effect is the same, but by using this function, the code is now shorter, and clearer. Also, if someone wants to change, say, the theme of the plot, now this only needs to be changed in one place and not for each commune. Now, what did the owner change? The owner started by removing the line that loaded the {purrr} package, as no function from the package was used in the script, and then also changed every %>% to |>. It seems that much more than just who would make the changes got lost in translation… Anyways, both now push their changes to their respective branches. This is Bruno:
bruno@computer ➤ git add .
bruno@computer ➤ git commit -m "make_plot() for plotting"
bruno@computer ➤ git push origin add_cool_featureEnumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 12 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 647 bytes | 647.00 KiB/s, done.
Total 3 (delta 1), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
remote:
remote: Create a pull request for 'add_cool_feature' on GitHub by visiting:
remote: https://github.com/rap4all/housing/pull/new/add_cool_feature
remote:
To github.com:rap4all/housing.git
* [new branch] add_cool_feature -> add_cool_featureand this is the owner:
owner@localhost ➤ git add .
owner@localhost ➤ git commit -m "cleanup"
owner@localhost ➤ git push origin add_sweet_featureEnumerating objects: 5, done.
Counting objects: 100% (5/5), done.
Delta compression using up to 4 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 449 bytes | 449.00 KiB/s, done.
Total 3 (delta 1), reused 0 (delta 0)
remote: Resolving deltas: 100% (1/1), completed with 1 local object.
remote:
remote: Create a pull request for 'add_sweet_feature' on GitHub by visiting:
remote: https://github.com/rap4all/housing/pull/new/add_sweet_feature
remote:
To github.com:rap4all/housing.git
* [new branch] add_sweet_feature -> add_sweet_featureSo, let’s think about what just happened: two developers changed the same file, analysis.R, in two separate branches. These two branches need to be merged back to the trunk.
So Bruno does a pull request:
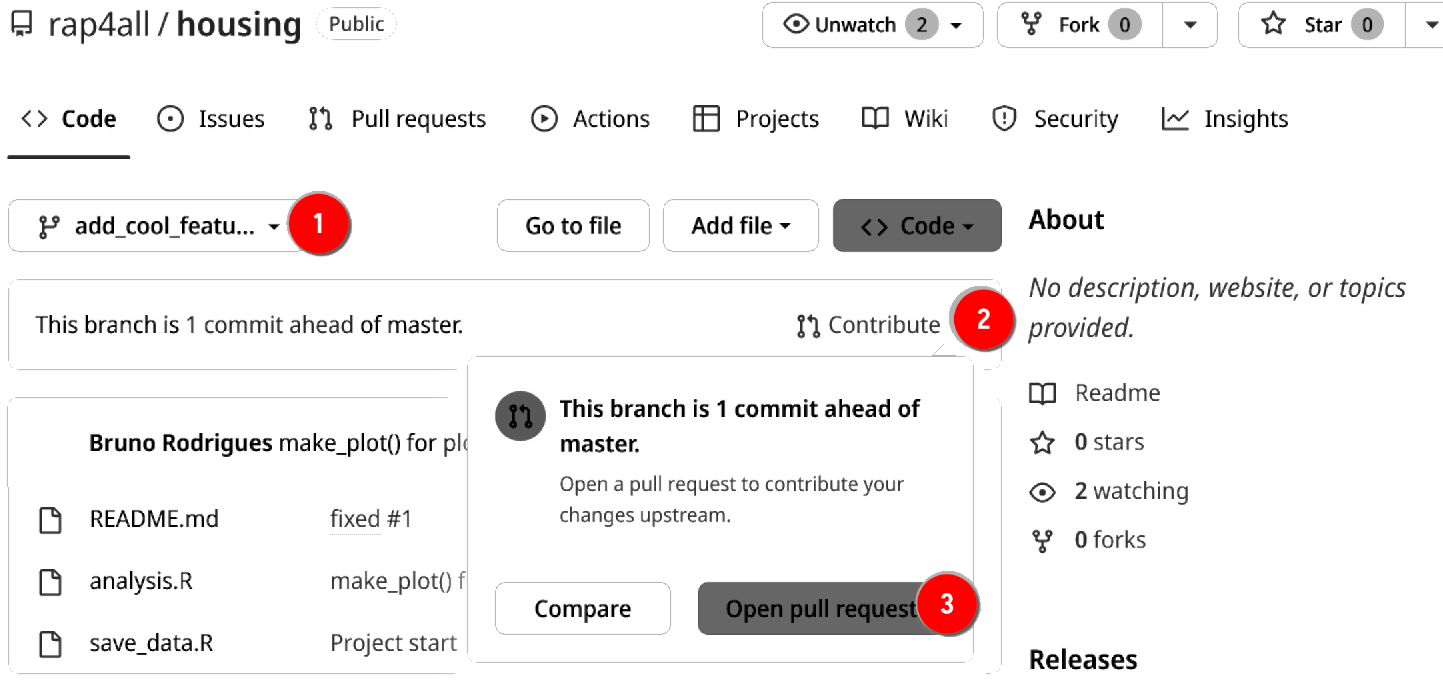
First, Bruno selects the feature branch (1), then clicks on “Contribute” (2) and then “Open pull request” (3). Bruno gets taken to this screen:
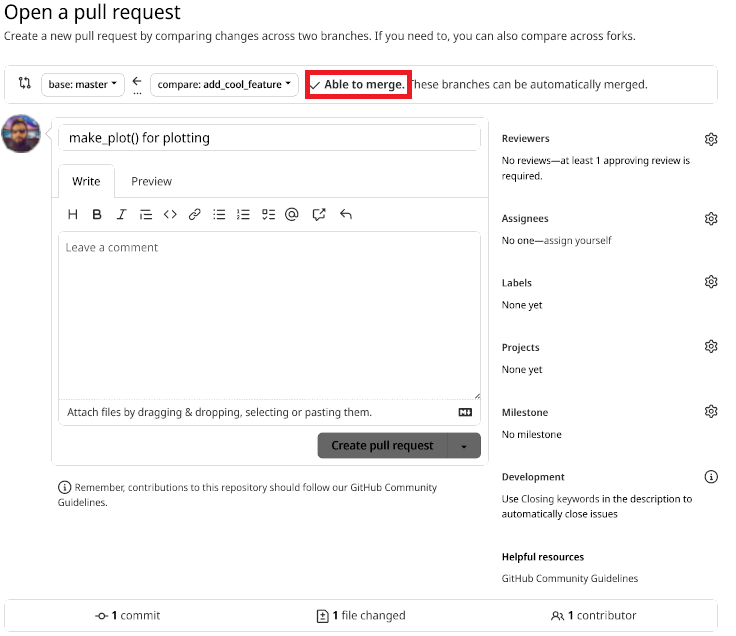
Now Bruno can click on “Create pull request”, but remember, because reviews are required, automatic merging is disabled.
If now we go see what happens from the project owner’s side of things, first of all, there’s now a notification for a pending review:
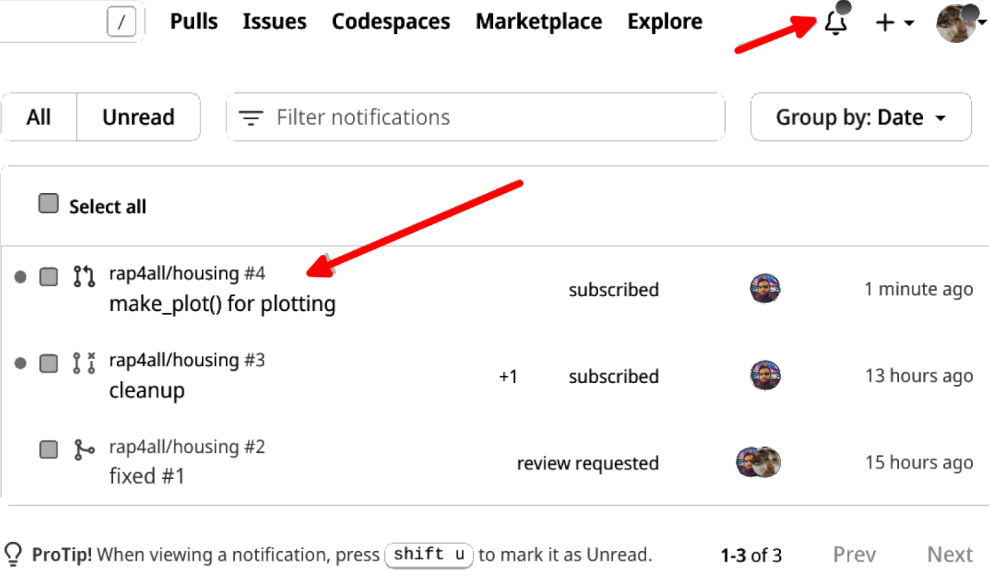
By clicking on it, the project owner can review the pull request and decide what to do with it. So at this point, the owner did not open a pull request for the feature he or she worked on yet. And maybe that’s a good thing, because now the project owner can see that the changes that Bruno made on the file will conflict with the project owner’s changes.
So how to move forward? Simple: the project owner can decide to approve the pull request, which will merge Bruno’s changes into the master branch (or the trunk). Then, instead of opening a pull request for merging his or her changes into trunk, which will cause a conflict, the project owner can instead merge the changes from the trunk into his or her feature branch. This will also create a conflict, but now the project owner can easily deal with it on his or her machine, and then push a new commit with both changes integrated gracefully. The image below illustrates this workflow:
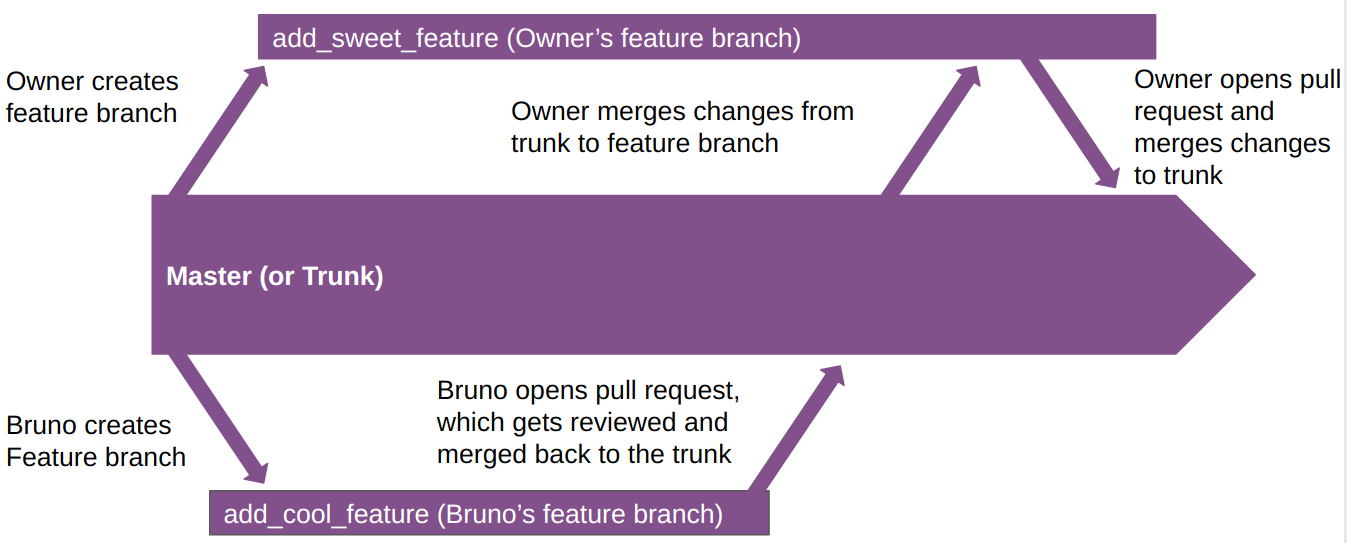
First step, the owner reviews and approves Bruno’s pull request:
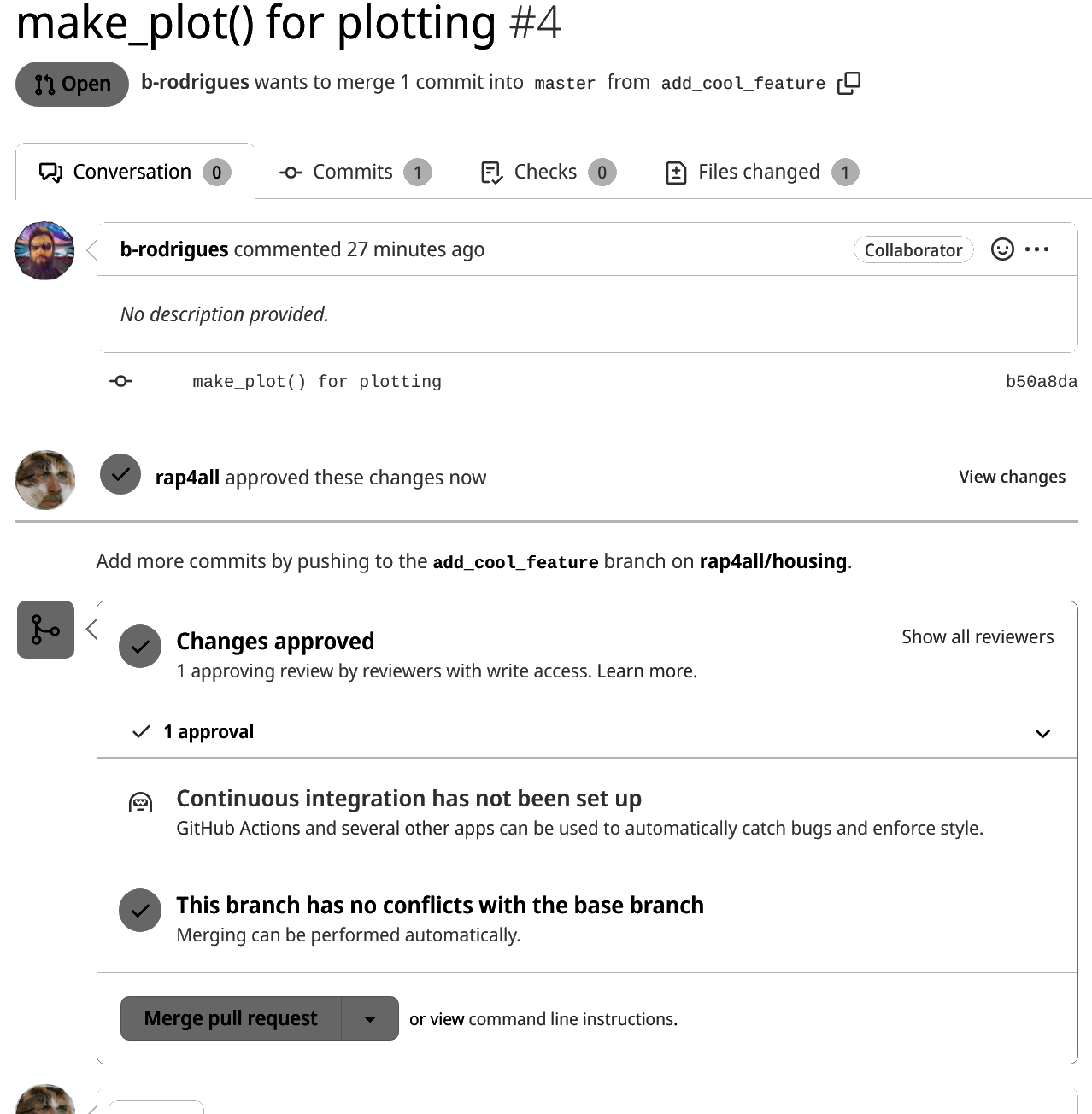
The pull request can get merged and Bruno’s feature branch deleted. Now, it wouldn’t make sense for the project owner to create a pull request to merge his or her changes. They would conflict with what Bruno did. So the project owner goes back to his or her computer and essentially updates the code in his or her feature branch by merging master into it.
So, the project owner checks that he or she is working on the feature branch:
owner@localhost ➤ git statusOn branch add_sweet_feature
nothing to commit, working tree cleanOk, so now let’s get the updated code from master, by pulling from master:
owner@localhost ➤ git pull origin masterThe owner now sees this:
remote: Enumerating objects: 6, done.
remote: Counting objects: 100% (6/6), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 4 (delta 1), reused 3 (delta 1), pack-reused 0
Unpacking objects: 100% (4/4), 1.23 KiB | 418.00 KiB/s, done.
From github.com:rap4all/housing
* branch master -> FETCH_HEAD
c774ebf..a43c68f master -> origin/master
Auto-merging analysis.R
CONFLICT (content): Merge conflict in analysis.R
Automatic merge failed; fix conflicts and then commit the result.Git detects that there are some conflicts and tells the owner to fix them, and then commit the results. So let’s open analysis.R and see how it looks (you can view the file online on this link1. First of all, you will see Git deals with conflicts on a per-line basis. So each line that the owner changed that does not conflict with Bruno’s change gets immediately updated to reflect the owner’s changes. For example, remember that the owner removed the line that loaded the {purrr} package? This line was also removed by pulling the changes from master into the feature branch. Also, you should notice that every %>% was changed into |> as well. These two changes happened without any issues.
Then, you should understand what happens when a conflict gets detected on some lines. For example, this is the first conflict you should see:
<<<<<<< HEAD
filtered_data <- commune_level_data |>
filter(locality == communes[1])
=======
filtered_data <- commune_level_data %>%
filter(locality == commune)
>>>>>>> a43c68f5596563ffca33b3729451bffc762782c3We see how the lines look on the owner’s computer and how they look in the master branch (or trunk). The lines between <<<<<<< HEAD and ======= are the lines in the owner’s feature branch. The lines between ======= and >>>>>>> a43c68f5596563ffca33b3729451bffc762782c3 are how they look in the master branch (or trunk). This very long chain of characters that starts with a43c68f is the hash of the commit from which these lines come from.
So this makes things quite easy; one simply needs to remove the outdated code, and then commit and push the fixed file! The project owner only needs to remove <<<<<<< HEAD and ======= and what’s between these lines, as well as the lines that show the hash commit. The project owner can now commit and push the changes, open a pull request, ask Bruno to review the changes one last time and merge everything back to master.
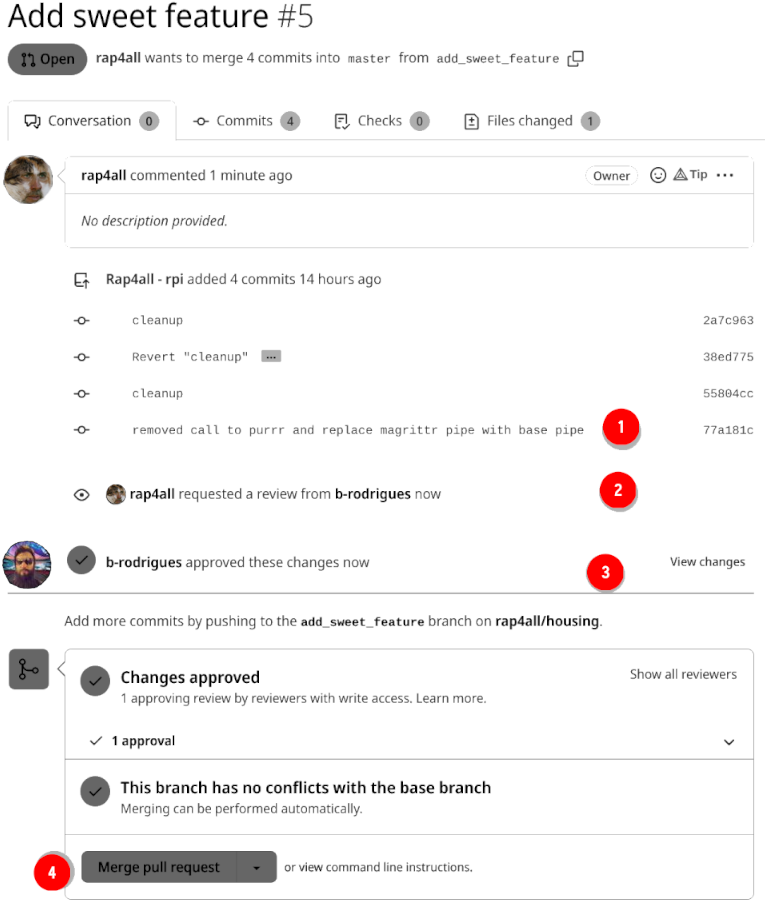
In (1) we see the commit that deals with the conflict, in (2) the owner asks Bruno for a review and then in (3) we see that Bruno reviewed and approved. Finally, the pull request can be merged (4) and the feature branch deleted.
5.1.3 Make sure you blame the right person
If many people contribute to a single project, it might sometimes be difficult to know who changed what and when exactly. This is where the git blame command is useful. If you want to know who changed the file called analysis.R for example, simply run:
owner@localhost ➤ git blame analysis.Rand you will see a detailed history, line by line, with the user name of the contributors and a date stamp:
b7f82ee1 (Bruno 2023-02-05 18:03:37 +0100 24) #Let’s also compute it...
b7f82ee1 (Bruno 2023-02-05 18:03:37 +0100 25)
55804ccb (Owner 2023-02-11 22:33:20 +0000 26) country_level_data <- ...
55804ccb (Owner 2023-02-11 22:33:20 +0000 27) mutate(p0 = ifelse(y...We can see that Bruno edited lines 24 and 25 on the 5th of February as part of the commit with the hash b7f82ee1, while the owner of the repository changed lines 26 and 27 on the 11th of February as part of the commit with the hash 55804ccb.
Take advantage of git blame to have a clear overview of each file’s changes.
5.1.4 Simplified trunk-based development
The workflow that we showed here may seem a bit too rigid for smaller teams (below 4 or 5 contributors). It is possible to adopt a simplified version of trunk-based development, where contributors don’t have to open pull requests to merge their feature branches into the trunk, and no reviewer is needed. In cases like this, Git forces you to pull changes if someone already merged his or her feature branch into the trunk before you could. This way, when pulling, conflicts (if any) arise at that point. It is then your responsibility to solve the conflicts (and this works just like in the previous section) and then commit and push the commits with the conflicts resolved. Another contributor who then wishes to merge his or her feature branch into the trunk will have to pull again, ensuring that conflicts get resolved before they can merge. If no conflicts arise (for example, you both worked on different files, or on different lines of the same files), then no resolution is needed and the feature branch can be merged into master.
5.1.5 Conclusion
The main ideas of trunk-based development are:
- Each contributor opens a new branch to develop a feature or fix a bug, and works alone on his or her own little branch;
- At the end of the day at the latest (or a previously agreed upon duration), branches need all to get merged;
- Conflicts need to be taken care of at that point;
- If adding a feature would take more time than just one day, then the task needs to be split in a manner that small contributions can be merged daily. In the beginning, these contributions can be simple placeholders that will be gradually enriched with functioning code until the feature is successfully implemented. This strategy is called branching by abstraction;
- The master branch (or trunk) always contains working, production-grade, code;
- To enforce discipline, it might be worth it to make opening pull requests mandatory for merging back to the trunk, and require a review.
5.2 Contributing to public repositories
In this last section, we are going to briefly discuss how to contribute to a project when we are not a team member of that project. For example, maybe we use an R package and notice a bug, and want to propose a fix. Or maybe we simply spotted a typo in the README of said package, and want to propose a correction. Whatever it may be, if the repository is public, anyone can propose a fix. For example, consider this repository:
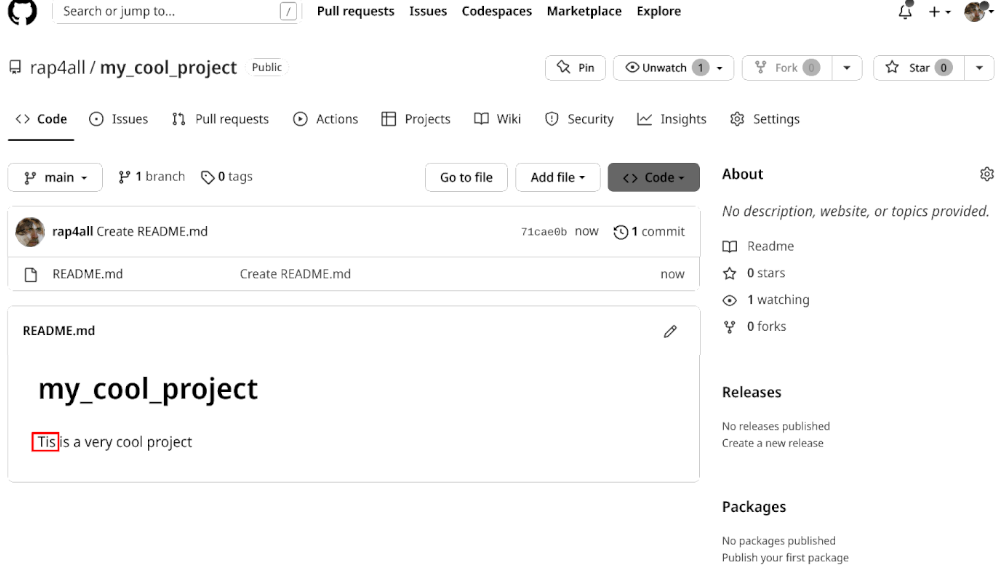
This repository contains code written by a fellow called “rap4all”, and Bruno uses this code daily. However, Bruno notices a typo in the readme, and wants to propose a fix.
First, Bruno visits the repository on Github (since it’s a public repository, anyone can view it online) and creates a fork:
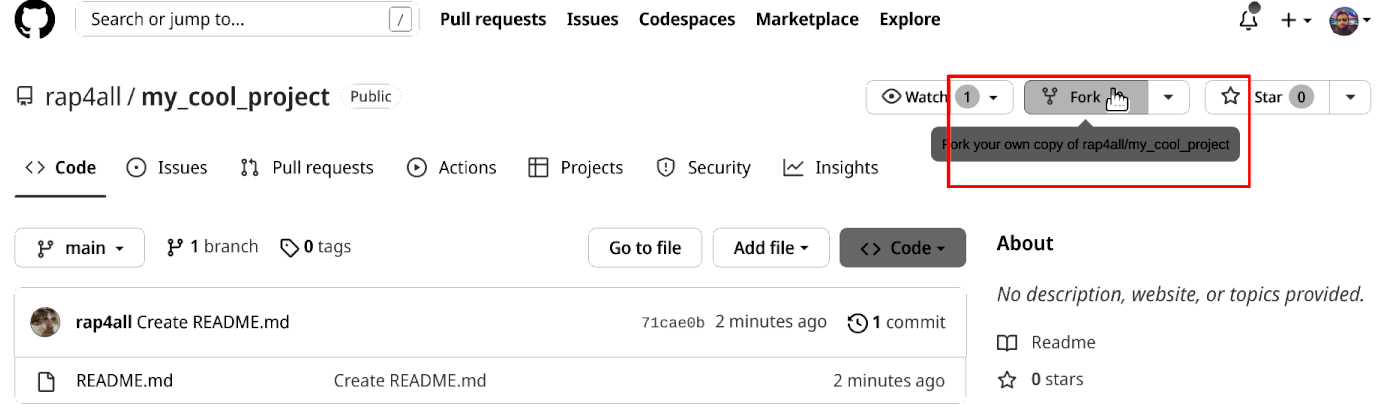
Forking creates a copy of the repository in Bruno’s account:
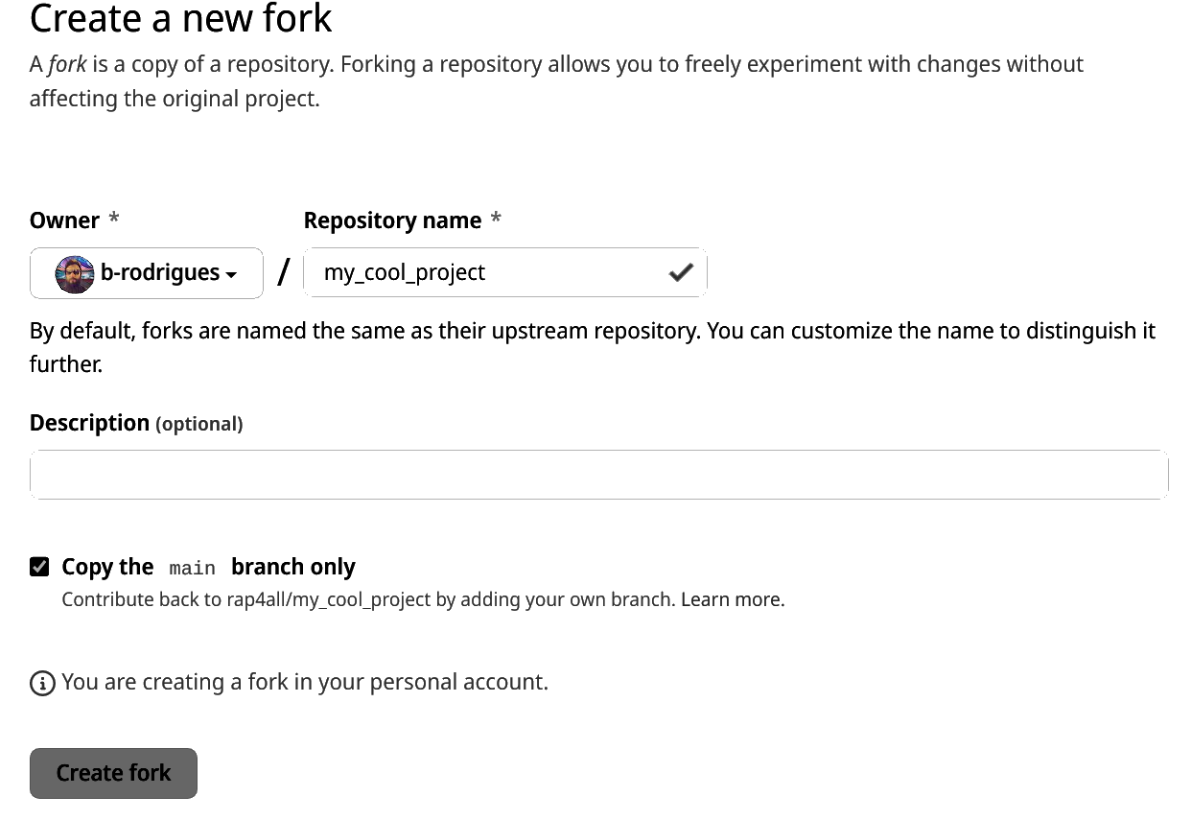
Bruno now sees the fork on his account as well:
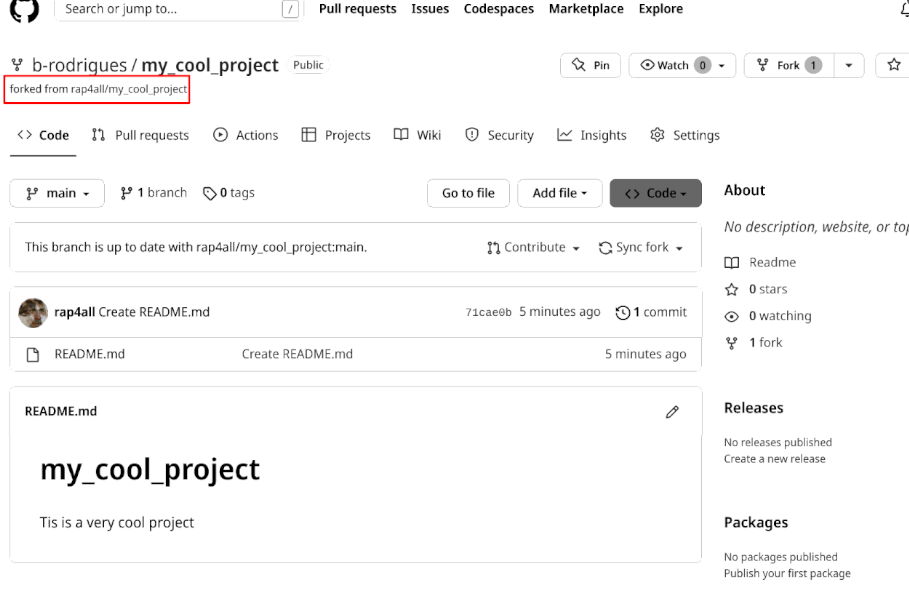
So now, Bruno can clone this repository and work on it, because he is working on a copy of the repository that he owns. Anything Bruno does on this copy will not affect the original repository:
bruno@computer ➤ git clone git@github.com:b-rodrigues/my_cool_project.git Bruno now fixes the typo in the README.md file, commits and pushes to his fork:
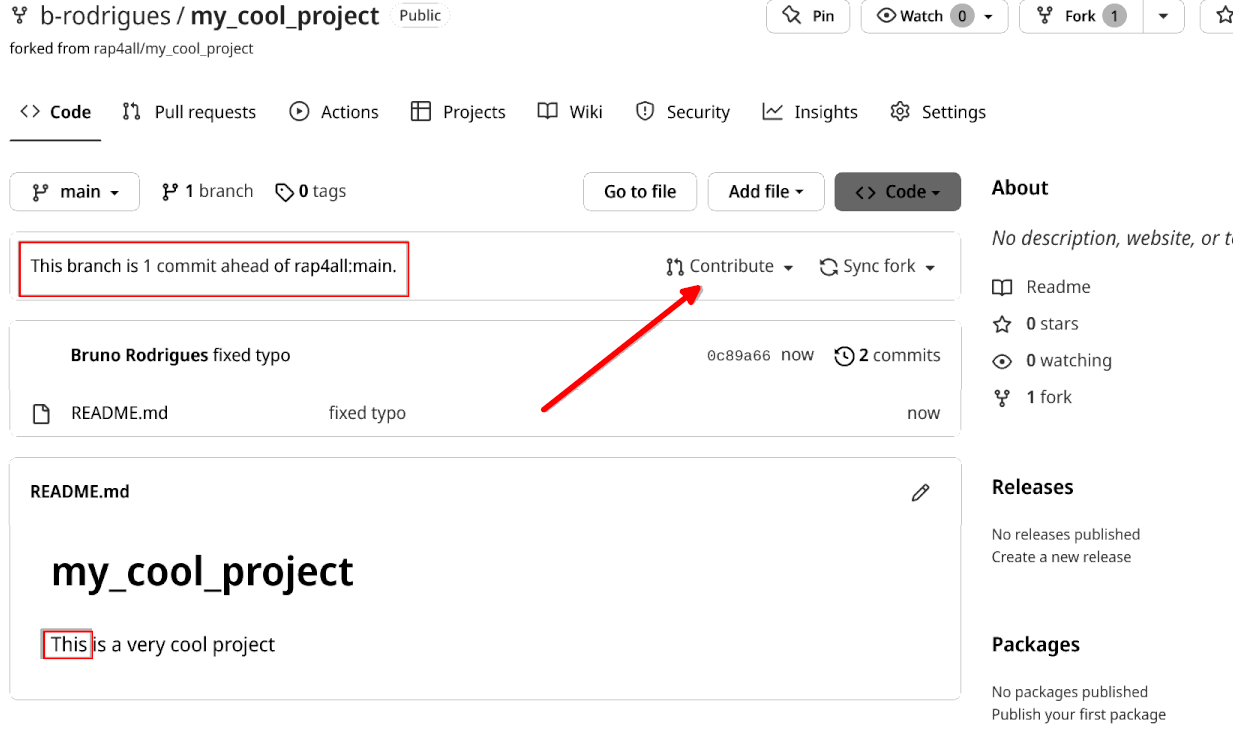
As you can see, Bruno’s fork is now ahead of the original repo by one commit. By clicking on “Contribute”, Bruno can open a pull request to propose his fix to the original repository.
This pull request will be opened over at the original repository:
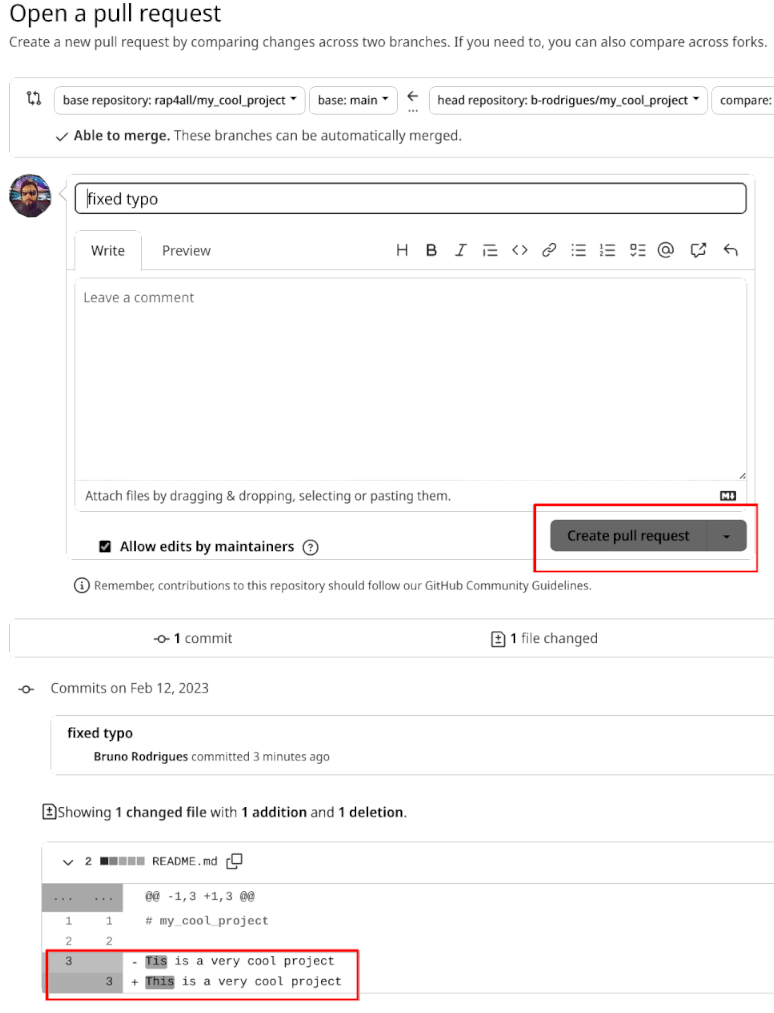
What does the owner of the original repository, “rap4all”, see? The pull request Bruno opened is now in the original repository’s “Pull request” menu, and the owner can check what the contribution is, if it breaks code or not, etc. This is essentially the same workflow as the one presented before in trunk-based development with pull requests and reviews before merging (minus the forking of the repository).
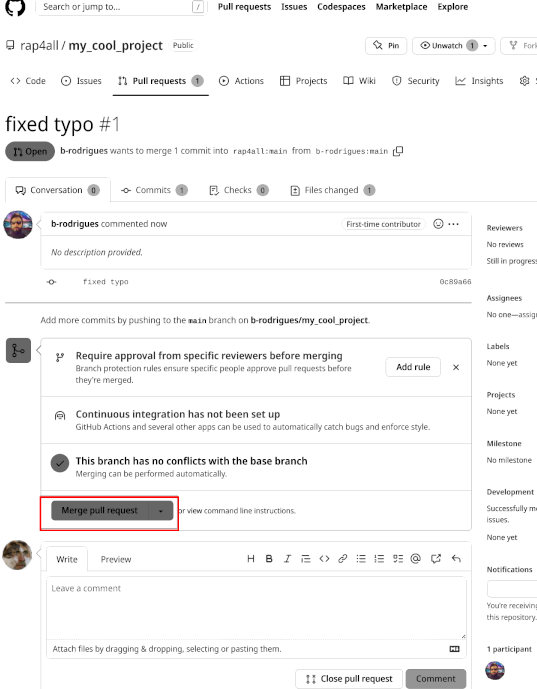
By merging the fix, the owner can now benefit from a grammatically correct Readme file as well:
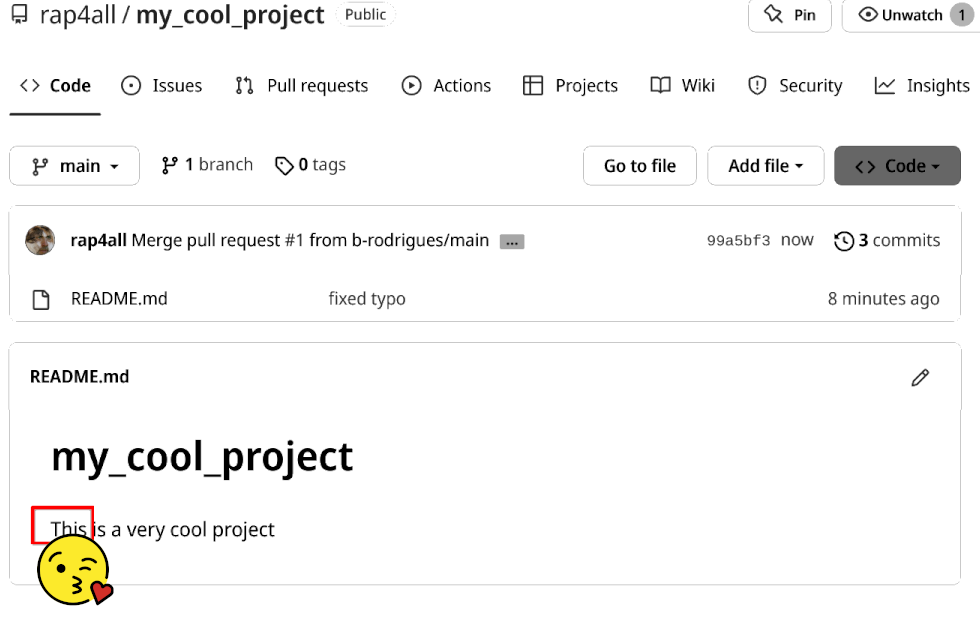
5.3 Further reading
To know everything about trunk-based development, check out Hammant (2020). A free, online, version of the book is available at https://trunkbaseddevelopment.com/.
https://is.gd/ktWtjr↩︎